
📊 Независимые бенчмарки gpt-oss от OpenAI
OpenAI выпустила два MoE-модели с открытым весом — и это, похоже, самые *интеллектуальные американские open-source LLM* на сегодня:
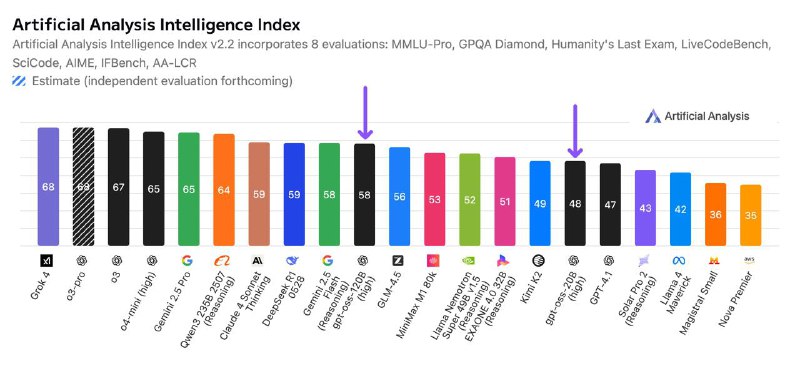
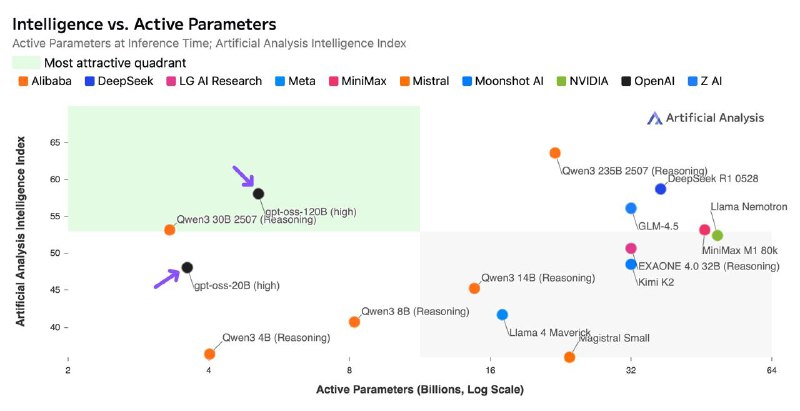
🧠 gpt-oss-120b (116.8B параметров, 5.1B активных): *Intelligence Index: 58*
🧠 gpt-oss-20b (20.9B параметров, 3.6B активных): *Intelligence Index: 48*
🏆 Что важно:
- gpt-oss-120b обходит o3-mini, уступая только o4-mini, DeepSeek R1 (59) и Qwen3 235B (64).
- Это *самая интеллектуальная модель*, которую можно запустить на одной H100.
- gpt-oss-20b — лидер среди моделей, которые можно запустить на ноутбуке с 16GB+ RAM.
💡 Эффективность и размер:
- MXFP4 precision: всего 60.8GB (120b) и 12.8GB (20b)
- 120B активирует только 4.4% параметров, в отличие от Llama 4 Scout с 17B активных
- Десятки токенов/с на MacBook для 20B
⚙️ Архитектура:
- MoE: top-4 эксперта на токен
- Rotary + YaRN, контекст: до 128K
- 36 слоёв / 64 головы / GQA с 8 KV
- 20B активирует ~17.2% параметров, больше, чем у 120B
📈 Сравнение с другими:
- DeepSeek R1: 671B total / 37B active, FP8, файл >10× больше
- Qwen3 235B: 64 балла, но тоже существенно тяжелее
🌐 Провайдеры API:
Тестируем:
💵 Цены (медиана):
- 120B: $0.15 / $0.69 за 1M токенов (ввод / вывод)
- 20B: $0.08 / $0.35
- Для сравнения: o4-mini — $1.1 / $4.4, o3 — $2 / $8 (!)
📄 Лицензия: Apache 2.0 — максимально свободно!
— GPT-OSS-120B — 117B параметров, запускается на одной H100 (80GB)
— GPT-OSS-20B — 21B параметров, работает на 16GB GPU
OpenAI выпустила два MoE-модели с открытым весом — и это, похоже, самые *интеллектуальные американские open-source LLM* на сегодня:
🧠 gpt-oss-120b (116.8B параметров, 5.1B активных): *Intelligence Index: 58*
🧠 gpt-oss-20b (20.9B параметров, 3.6B активных): *Intelligence Index: 48*
🏆 Что важно:
- gpt-oss-120b обходит o3-mini, уступая только o4-mini, DeepSeek R1 (59) и Qwen3 235B (64).
- Это *самая интеллектуальная модель*, которую можно запустить на одной H100.
- gpt-oss-20b — лидер среди моделей, которые можно запустить на ноутбуке с 16GB+ RAM.
💡 Эффективность и размер:
- MXFP4 precision: всего 60.8GB (120b) и 12.8GB (20b)
- 120B активирует только 4.4% параметров, в отличие от Llama 4 Scout с 17B активных
- Десятки токенов/с на MacBook для 20B
⚙️ Архитектура:
- MoE: top-4 эксперта на токен
- Rotary + YaRN, контекст: до 128K
- 36 слоёв / 64 головы / GQA с 8 KV
- 20B активирует ~17.2% параметров, больше, чем у 120B
📈 Сравнение с другими:
- DeepSeek R1: 671B total / 37B active, FP8, файл >10× больше
- Qwen3 235B: 64 балла, но тоже существенно тяжелее
🌐 Провайдеры API:
Тестируем:
@GroqInc, @CerebrasSystems, @FireworksAI_HQ, @togethercompute💵 Цены (медиана):
- 120B: $0.15 / $0.69 за 1M токенов (ввод / вывод)
- 20B: $0.08 / $0.35
- Для сравнения: o4-mini — $1.1 / $4.4, o3 — $2 / $8 (!)
📄 Лицензия: Apache 2.0 — максимально свободно!
— GPT-OSS-120B — 117B параметров, запускается на одной H100 (80GB)
— GPT-OSS-20B — 21B параметров, работает на 16GB GPU
👍6❤2👎1🥰1
tgoop.com/machinelearning_ru/2855
Create:
Last Update:
Last Update:
📊 Независимые бенчмарки gpt-oss от OpenAI
OpenAI выпустила два MoE-модели с открытым весом — и это, похоже, самые *интеллектуальные американские open-source LLM* на сегодня:
🧠 gpt-oss-120b (116.8B параметров, 5.1B активных): *Intelligence Index: 58*
🧠 gpt-oss-20b (20.9B параметров, 3.6B активных): *Intelligence Index: 48*
🏆 Что важно:
- gpt-oss-120b обходит o3-mini, уступая только o4-mini, DeepSeek R1 (59) и Qwen3 235B (64).
- Это *самая интеллектуальная модель*, которую можно запустить на одной H100.
- gpt-oss-20b — лидер среди моделей, которые можно запустить на ноутбуке с 16GB+ RAM.
💡 Эффективность и размер:
- MXFP4 precision: всего 60.8GB (120b) и 12.8GB (20b)
- 120B активирует только 4.4% параметров, в отличие от Llama 4 Scout с 17B активных
- Десятки токенов/с на MacBook для 20B
⚙️ Архитектура:
- MoE: top-4 эксперта на токен
- Rotary + YaRN, контекст: до 128K
- 36 слоёв / 64 головы / GQA с 8 KV
- 20B активирует ~17.2% параметров, больше, чем у 120B
📈 Сравнение с другими:
- DeepSeek R1: 671B total / 37B active, FP8, файл >10× больше
- Qwen3 235B: 64 балла, но тоже существенно тяжелее
🌐 Провайдеры API:
Тестируем:
💵 Цены (медиана):
- 120B: $0.15 / $0.69 за 1M токенов (ввод / вывод)
- 20B: $0.08 / $0.35
- Для сравнения: o4-mini — $1.1 / $4.4, o3 — $2 / $8 (!)
📄 Лицензия: Apache 2.0 — максимально свободно!
— GPT-OSS-120B — 117B параметров, запускается на одной H100 (80GB)
— GPT-OSS-20B — 21B параметров, работает на 16GB GPU
OpenAI выпустила два MoE-модели с открытым весом — и это, похоже, самые *интеллектуальные американские open-source LLM* на сегодня:
🧠 gpt-oss-120b (116.8B параметров, 5.1B активных): *Intelligence Index: 58*
🧠 gpt-oss-20b (20.9B параметров, 3.6B активных): *Intelligence Index: 48*
🏆 Что важно:
- gpt-oss-120b обходит o3-mini, уступая только o4-mini, DeepSeek R1 (59) и Qwen3 235B (64).
- Это *самая интеллектуальная модель*, которую можно запустить на одной H100.
- gpt-oss-20b — лидер среди моделей, которые можно запустить на ноутбуке с 16GB+ RAM.
💡 Эффективность и размер:
- MXFP4 precision: всего 60.8GB (120b) и 12.8GB (20b)
- 120B активирует только 4.4% параметров, в отличие от Llama 4 Scout с 17B активных
- Десятки токенов/с на MacBook для 20B
⚙️ Архитектура:
- MoE: top-4 эксперта на токен
- Rotary + YaRN, контекст: до 128K
- 36 слоёв / 64 головы / GQA с 8 KV
- 20B активирует ~17.2% параметров, больше, чем у 120B
📈 Сравнение с другими:
- DeepSeek R1: 671B total / 37B active, FP8, файл >10× больше
- Qwen3 235B: 64 балла, но тоже существенно тяжелее
🌐 Провайдеры API:
Тестируем:
@GroqInc, @CerebrasSystems, @FireworksAI_HQ, @togethercompute💵 Цены (медиана):
- 120B: $0.15 / $0.69 за 1M токенов (ввод / вывод)
- 20B: $0.08 / $0.35
- Для сравнения: o4-mini — $1.1 / $4.4, o3 — $2 / $8 (!)
📄 Лицензия: Apache 2.0 — максимально свободно!
— GPT-OSS-120B — 117B параметров, запускается на одной H100 (80GB)
— GPT-OSS-20B — 21B параметров, работает на 16GB GPU
BY Машинное обучение RU
Share with your friend now:
tgoop.com/machinelearning_ru/2855