tgoop.com/machinelearning_ru/2474
Last Update:
InfiniteHiP - опенсорсный инструмент, разработанный сервисом deepauto.ai, который позволяет значительно расширить контекст LLM, обрабатывая до 3 миллионов токенов на одном GPU.
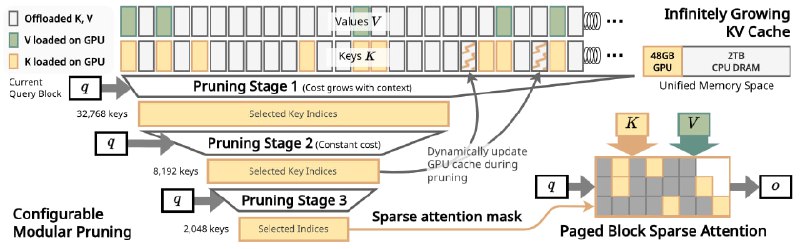
InfiniteHiP использует модульный иерархический алгоритм прунинга токенов, динамически отсеивая нерелевантные элементы контекста. Это позволяет ускорить обработку и обойти ограничения GPU по памяти, перенося KV-кэш в память хоста.
Прунинг-модули алгоритма избирательно отбрасывают менее важные входные токены, опираясь на разреженность шаблонов и пространственную локализацию в матрицах внимания LLM.
Алгоритм делит входную последовательность на чанки фиксированной длины и определяет аппроксимированный top-1 токен с наивысшим attention score в каждом чанке. Затем только top-K наиболее значимых чанков передаются в следующий модуль, а остальные отбрасываются.
Максимально эффективная реализация InfiniteHiP на SGLang фреймворке показывает 7.24-кратное ускорение в end-to-end декодировании на контексте в 3 млн. при использовании всего 3.34% VRAM, необходимой для Flash Attention 2.
InfiniteHiP превосходит существующие методы в задачах QA по объемным документам, обобщении и в мульти-шот ризонинге. HiP демонстрирует отличные OOL (out-of-likelihood) способности, сохраняя производительность при увеличении длины контекста, в то время как другие методы на таких задачах ощутимо деградируют.
InfiniteHiP может использоваться с любыми моделями на архитектуре Transformers.
git clone [email protected]:DeepAuto-AI/hip-attention.git
cd hip-attention
conda create --name hip python=3.11
conda activate hip
pip install -e "."
# Optional for development
pip install -e ".[dev]"
# Optional, depends on your CUDA environment
export CUDACXX=/usr/local/cuda/bin/nvcc
# Dependencies that requires --no-build-isolation
pip install -e ".[no_build_iso]" \
--no-build-isolation \
--verbose
# SGLang with OpenAI API support for serving
pip install -e ".[sglang]" \
--no-build-isolation \
--verbose \
--find-links https://flashinfer.ai/whl/cu124/torch2.4/flashinfer/
# Access the `hip` package from any project
import torch
from hip import hip_attention_12, HiPAttentionArgs12
device = 'cuda'
batch_size = 1
kv_len = 128 * 1024
q_len = 32 * 1024
num_heads = 32
num_kv_heads = 8
head_dims = 128
dtype = torch.bfloat16
q = torch.randn(
(batch_size, q_len, num_heads, head_dims),
dtype=dtype,
device=device
)
k = torch.randn(
(batch_size, kv_len, num_kv_heads, head_dims),
dtype=dtype,
device=device,
)
v = k.clone()
output, metadata = hip_attention_12(q=q, k=k, v=v, args=HiPAttentionArgs12())
print(output.shape)
# > torch.Size([1, 32768, 32, 128])
@ai_machinelearning_big_data
#AI #ML #InfiniteHiP #Framework