tgoop.com/machinelearning_ru/2414
Create:
Last Update:
Last Update:
Mixture-of-Mamba — экспериментальная архитектура, которая делает мультимодальные модели (работающие с разными типами данных, например, текстом, изображениями и речью) более эффективными и быстрыми. Она использует идею разреженности, чтобы уменьшить количество вычислений, сохраняя при этом высокое качество работы модели.
Разреженность — это подход, при котором модель фокусируется только на приоритетных данных, игнорируя менее значимые. Это похоже на то, как человек читает текст: мы не вникаем в каждую букву, а схватываем ключевые слова и фразы. В ML разреженность позволяет: уменьшить вычислительные затраты, ускорить обучение и инференс, повысить качество.
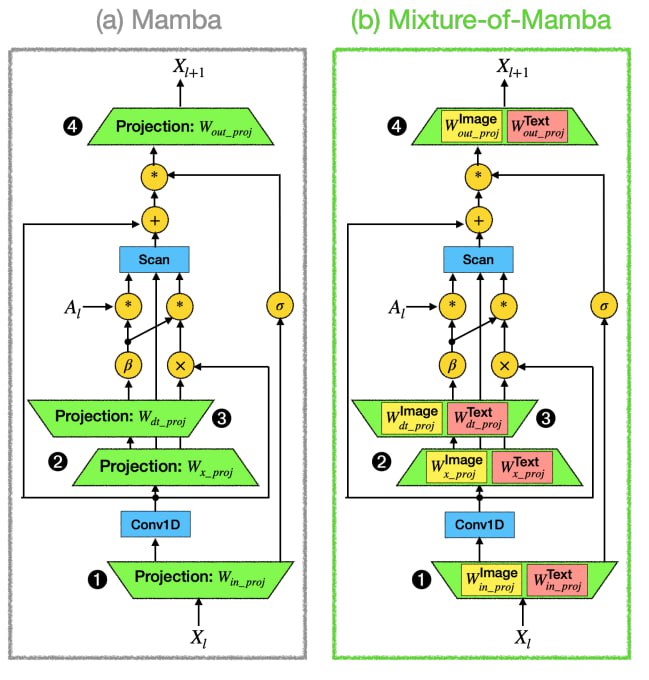
Mixture-of-Mamba добавляет модально-ориентированную разреженность в блоки Mamba и динамически выбирает модально-специфичные веса в каждом компоненте обработки ввода блоков Mamba.
В отличие от MoE-Mamba, где разреженность применяется только к MLP-слоям, Mixture-of-Mamba модифицирует непосредственно структуру блока Mamba. Модально-специфичная параметризация применяется к входной проекции, промежуточным и выходной проекциям. Сверточные слои и переходы состояний остаются общими.
Обучение Mixture-of-Mamba происходит в 3 модальных режимах: Transfusion (чередование текста и непрерывных токенов изображений с диффузионной потерей), Chameleon (чередование текста и дискретных токенов изображений) и расширенная трехмодальная среда со включением речи.
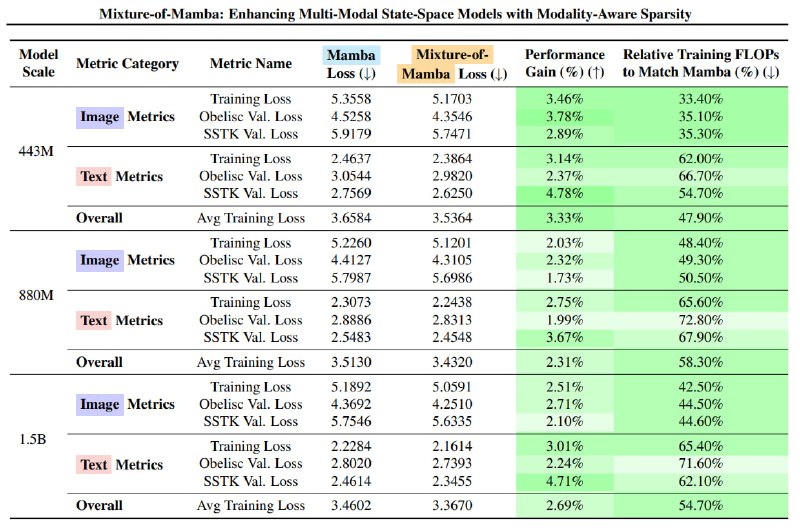
В Transfusion Mixture-of-Mamba достигает эквивалентных значений потерь для изображений, используя при этом лишь 34.76% от общего объема вычислительных ресурсов (FLOPs) при масштабе модели 1.4B. В сценарии Chameleon аналогичный уровень потерь при обработке изображений при использовании 42.50% FLOPs, а при обработке текстовых данных – 65.40% FLOPs. В трехмодальной среде Mixture-of-Mamba показывает потери в речевом режиме при 24.80% FLOPs на масштабе 1.4B.
@ai_machinelearning_big_data
#AI #ML #MMLM #Mamba #MixtureOfMamba