tgoop.com/machinelearning_ru/2318
Last Update:
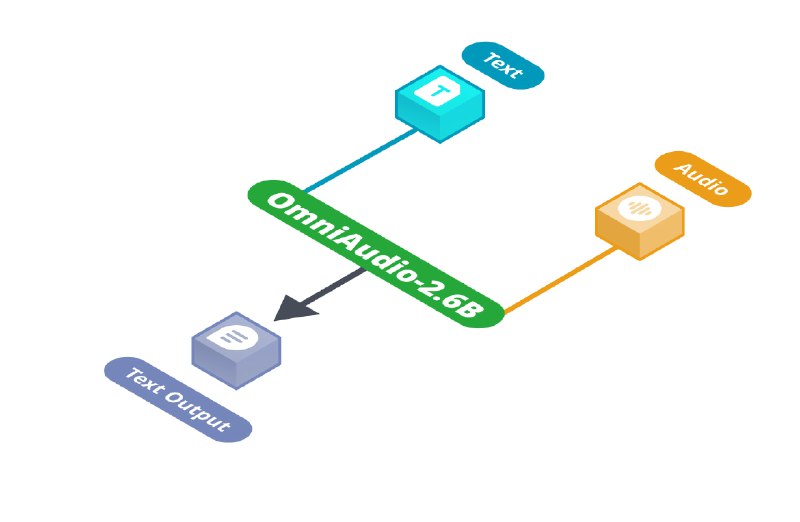
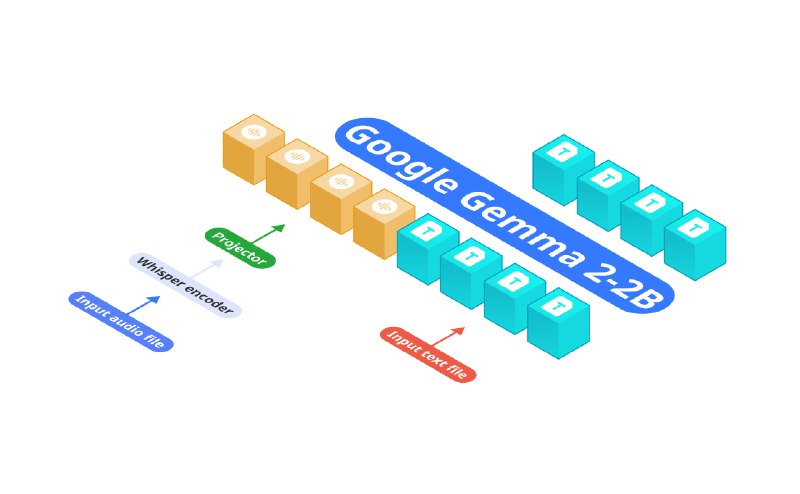
OmniAudio - мультимодальная модель с 2.6 млрд. параметров, объединяющая в себе Gemma-2-2b, Whisper turbo и специализированный проекционный модуль для обработки аудио и текста на потребительских устройствах. В отличие от традиционных подходов, использующих последовательное соединение моделей ASR и LLM, OmniAudio, объединяет эти функции в единой архитектуре, минимизируя задержку инференса и потребление ресурсов.
OmniAudio применима в сценариях голосовых запросов в автономном режиме, ведения диалогов, генерации контента, создания кратких обзоров записей и модификации интонации голоса.
Например, можно задать вопрос "Как развести костер без спичек?" и получить полезные инструкции, не имея подключения к Интернет. Модель может поддержать беседу, если вы скажете "У меня сегодня был тяжелый день на работе", или сгенерировать хайку на тему осенних листьев. OmniAudio способна преобразовать обычную голосовую заметку в формальное сообщение, сохраняя при этом основную идею.
OmniAudio обучалась в три этапа:
Производительность модели была протестирована на потребительском оборудовании. На Mac Mini M4 Pro модель Qwen2-Audio-7B-Instruct, работающая на Transformers, достигла скорости декодирования 6.38 токенов в секунду.
В то же время OmniAudio через Nexa SDK показала 35.23 токенов в секунду в формате FP16 GGUF и 66 токенов в секунду в квантованном формате Q4_K_M GGUF.
Модель опубликовала в 4 вариантах квантования в формате GGUF:
⚠️ Разработчик рекомендует локальный инференс в Nexa-SDK, опенсорс-фреймворке на основе GGLM, написанный на C++ для инференса моделей разных модальностей.
⚠️ В качестве ориентира по планированию ресурсов: для запуска OmniAudio версии q4_K_M требуется 1.30GB RAM.
@ai_machinelearning_big_data
#AI #ML #OmniAudio #NexaAI