tgoop.com/machinelearning_ru/2171
Last Update:
OpenCoder - это открытое и воспроизводимое семейство LLM для программирования, включающее 1,5B и 8B базовые и instruct версии, поддерживающее английский и китайский языки.
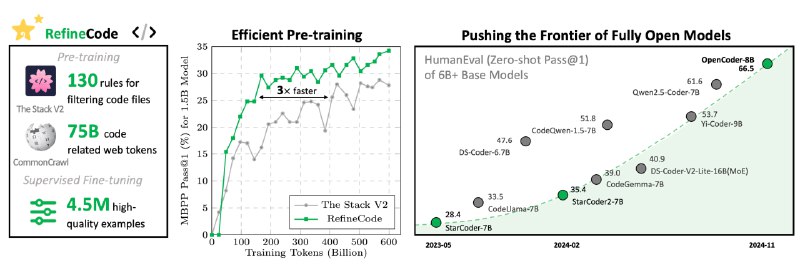
Семейство моделей OpenCoder обучалось с нуля на 2,5 трлн. лексем, состоящих на 90 % из сырого кода и на 10 % из веб-данных, связанных с кодом, и прошло отладку на более чем 4,5 млн. высококачественных примеров SFT, в итоге достигнув производительности топовых LLM с похожей специализацией.
В открытый доступ опубликованы не только веса моделей и код для инференса, но и датасеты, полный цикл обработки данных, результаты экспериментальной абляции и подробные протоколы обучения.
OpenCoder тщательно протестирован с помощью исследований абляции на различных стратегиях очистки данных и процессах обучения, включая эксперименты по дедупликации на уровне файлов и репозиториев, что обеспечило семейству тщательную проверку производительности моделей.
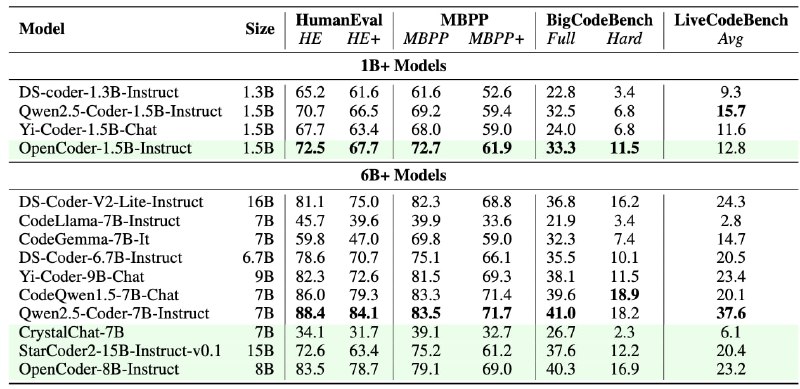
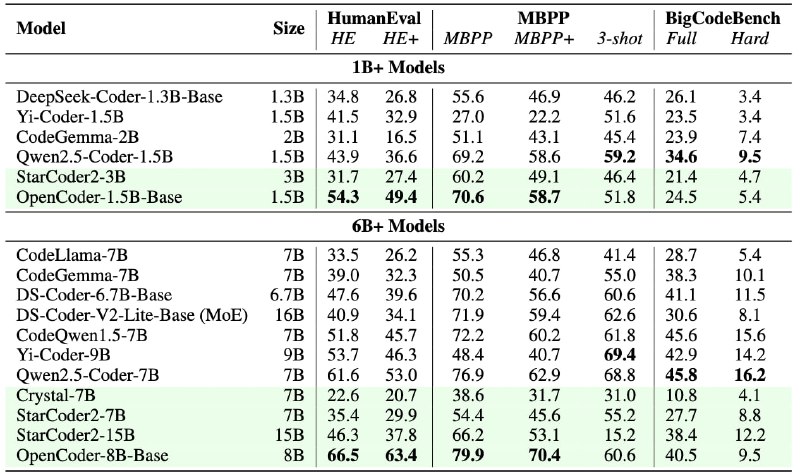
OpenCoder достигает высокой производительности в различных бенчмарках, что ставит их в ряд SOTA-моделей с открытым исходным кодом для задач программирования.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "infly/OpenCoder-8B-Instruct"
model = AutoModelForCausalLM.from_pretrained(model_name,
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
messages=[
{ 'role': 'user', 'content': "write a quick sort algorithm in python."}
]
inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
outputs = model.generate(inputs, max_new_tokens=512, do_sample=False)
result = tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True)
@ai_machinelearning_big_data
#AI #ML #LLM #OpenCoder #Datasets