tgoop.com/machinelearning_interview/1694
Last Update:
Исследователи из Google Research представили ECLeKTic — новый бенчмарк, предназначенный для оценки способности больших языковых моделей (LLM) переносить знания между языками.
Исследование направлено на выявление того, насколько эффективно модели могут применять информацию, полученную на одном языке, для решения задач на другом.
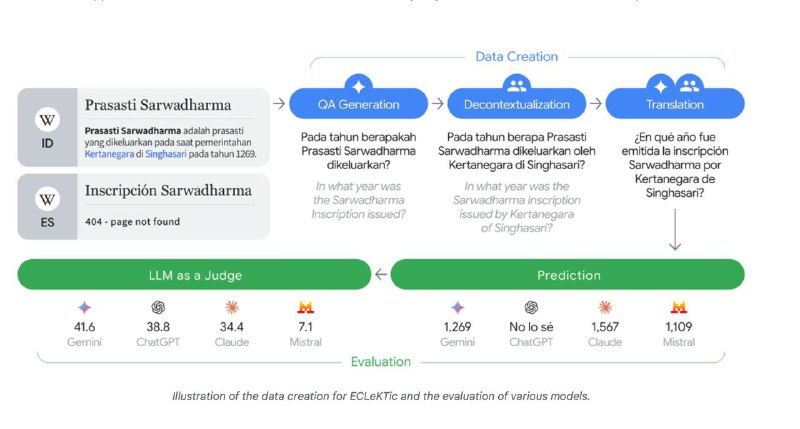
Бенчмарк включает вопросы, сформулированные на одном языке, ответы на которые содержатся в соответствующих статьях Википедии. Эти вопросы затем переводятся на другие языки, для которых аналогичных статей нет. Таким образом, модели должны демонстрировать способность извлекать и применять знания, отсутствующие в целевом языке.
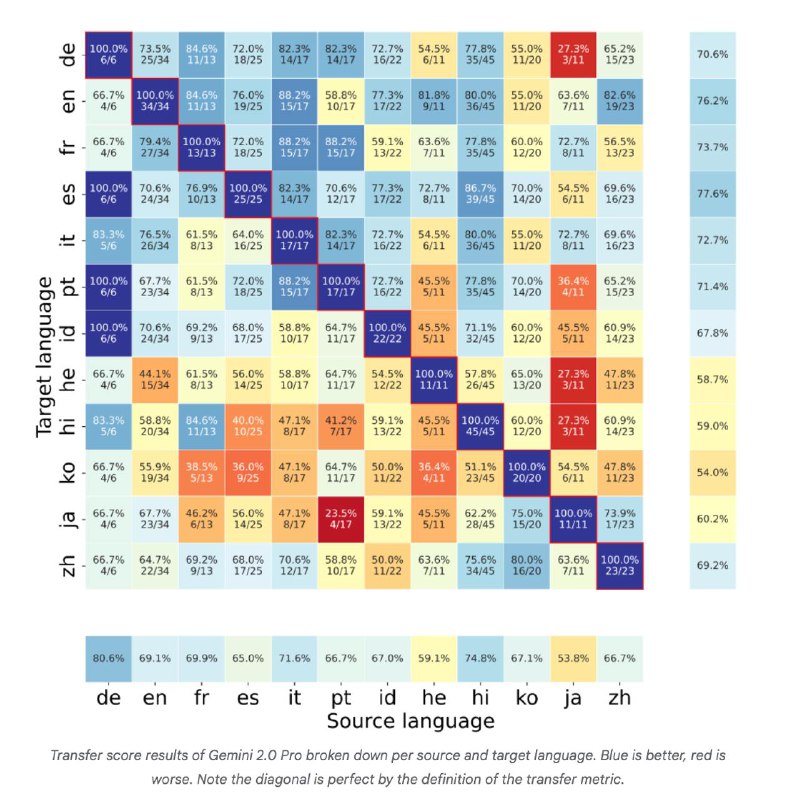
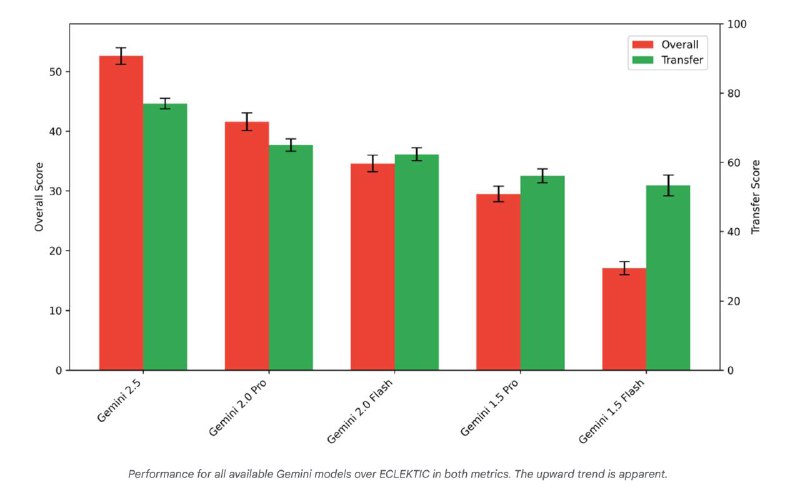
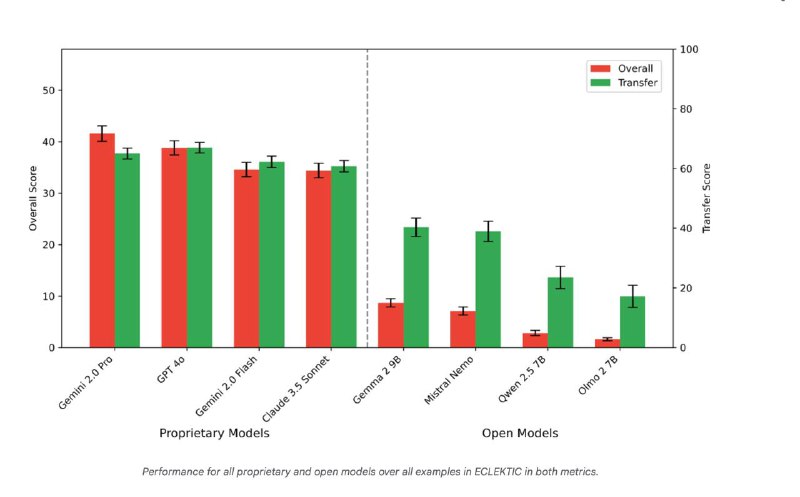
Оценка моделей: Испытания восьми современных LLM показали, что даже передовые модели испытывают трудности с межъязыковым переносом знаний. Это подчеркивает необходимость дальнейших исследований и улучшений в этой области.
Вместо простых вопросов используются тесты с множественным выбором, где неправильные ответы (дистракторы) специально сделаны очень похожими на правильный и правдоподобными. Чтобы выбрать верный вариант, модели нужно действительно понять нюансы на целевом языке, а не угадывать.
Минимизация "артефактов перевода": Вопросы тщательно создавались экспертами на 10 различных языках (включая арабский, хинди, японский, русский и др.). Они адаптированы культурно и лингвистически так, чтобы стратегия "перевести-решить-перевести обратно" работала плохо.
ECLECTIC – сложный тест: Он выявляет слабости в понимании, которые могут быть не видны на других бенчмарках.
Результаты показывают, что текущим LLM еще предстоит улучшить способность по-настоящему переносить и применять знания между языками.
@ai_machinelearning_big_data
#AI #ml #google #benchmark