tgoop.com/machinelearning_interview/1381
Last Update:
PRIME Intellect опубликовала INTELLECT-1 (Instruct + Base), первую языковую модель с 10 млрд. параметров, совместно обученную за 50 суток 30 участниками эксперимента по всему миру.
PRIME Intellect использовала собственную платформу PRIME, разработанную для решения главных проблем децентрализованного обучения: ненадежность сети и динамическое управление вычислительными узлами.
Платформа использовала сеть из 112 GPU H100 на 3 континентах и достигла коэффициента использования вычислений в 96% при оптимальных условиях.
Корпус обучения составлял на 1 трлн. токенов публичных датасетов с процентным соотношением: 55% fineweb-edu, 10% fineweb, 20% Stack V1, 10% dclm-baseline, 5% open-web-math.
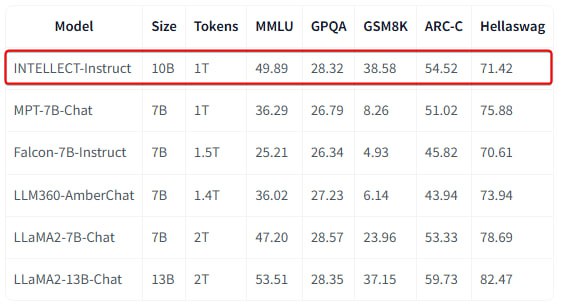
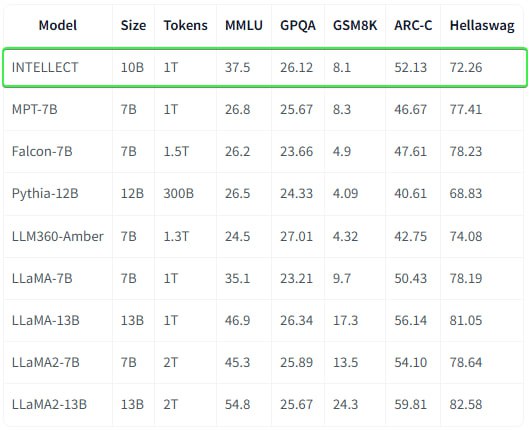
INTELLECT-1 достигла точности 37,5% на тесте MMLU и 72,26% на HellaSwag и превзошла несколько других моделей с открытым исходным кодом в WinoGrande с результатом 65,82%.
Хотя эти показатели немного отстают от современных популярных моделей, результаты эксперимента - важнейший шаг к демократизации разработки ИИ и предотвращению консолидации возможностей ИИ в рамках нескольких организаций.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
torch.set_default_device("cuda")
model = AutoModelForCausalLM.from_pretrained("PrimeIntellect/INTELLECT-1")
tokenizer = AutoTokenizer.from_pretrained("PrimeIntellect/INTELLECT-1")
input_text = "%prompt%"
input_ids = tokenizer.encode(input_text, return_tensors="pt")
output_ids = model.generate(input_ids, max_length=50, num_return_sequences=1)
output_text = tokenizer.decode(output_ids[0], skip_special_tokens=True)
print(output_text)
@ai_machinelearning_big_data
#AI #ML #LLM #Decentralizated