tgoop.com/machinelearning_interview/1377
Last Update:
QwQ (Qwen with Questions) – экспериментальная исследовательская модель, разработанная Qwen Team с фокусом на развитие способности рассуждения.
QwQ отличается любознательностью, подходя к каждой проблеме – будь то математика, программирование или знания о мире – с подлинным удивлением и сомнением. Прежде чем остановиться на каком-либо ответе, модель подвергает сомнению свои собственные предположения, исследуя разные пути рассуждений в поисках более глубокой истины.
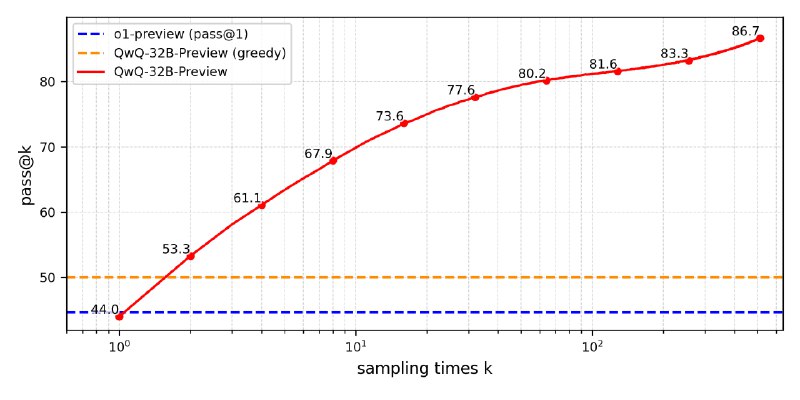
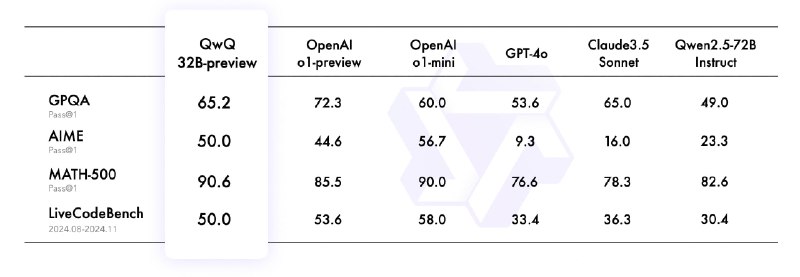
QwQ-32B-Preview, предварительная версия модели, которая демонстрирует аналитические способности в математике и программировании, показывая топовые результаты в тестах:
Архитектура QwQ основана на transformers с использованием RoPE, SwiGLU, RMSNorm и Attention QKV bias. Модель имеет 32.5 млрд. параметров, 64 слоя и 40 attention heads для Q и 8 для KV. Контекст модели - 32 768 токенов.
⚠️ Как у любого эксперимента, у QwQ есть ограничения:
⚠️ Сообществом LM Studio опубликованы квантованные версии в формате GGUF в разрядности от 3-bit (17.2 Gb) до 8-bit (34.8 GB), совместимые для запуска в llama.cpp (release b4191) и LM Studio.
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/QwQ-32B-Preview"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "How many r in strawberry."
messages = [
{"role": "system", "content": "You are a helpful and harmless assistant. You are Qwen developed by Alibaba. You should think step-by-step."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
@ai_machinelearning_big_data
#AI #ML #LLM #QwQ #Qwen