📌 Яндекс добавил в Нейро новую мультимодальную VLM для поиска по картинкам
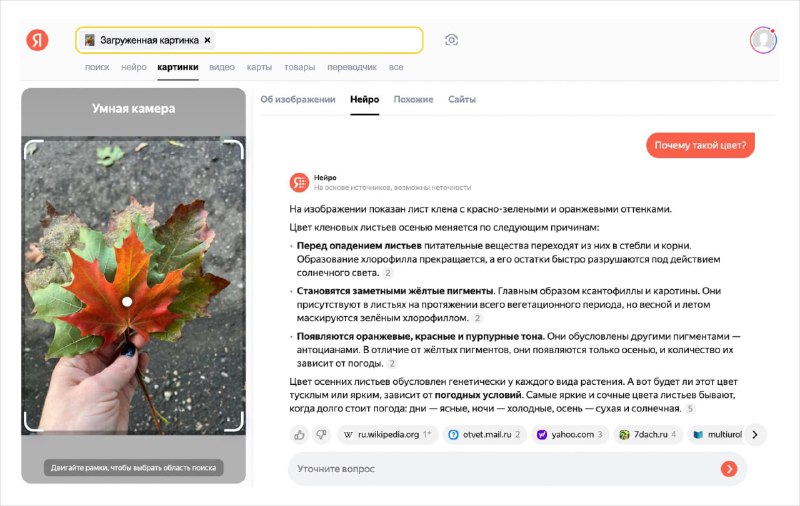
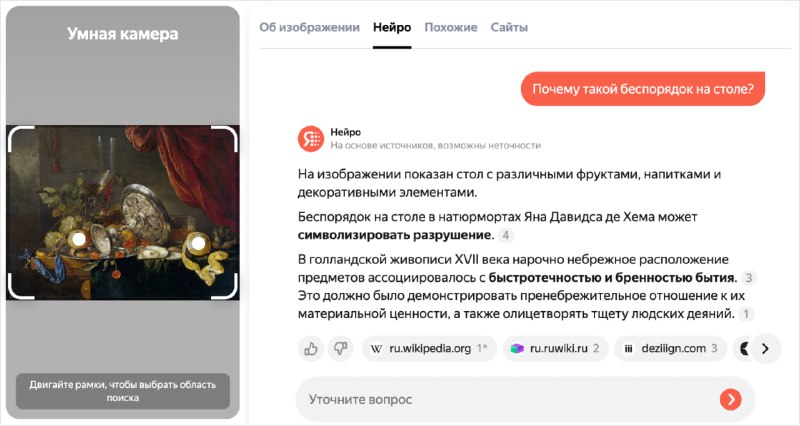
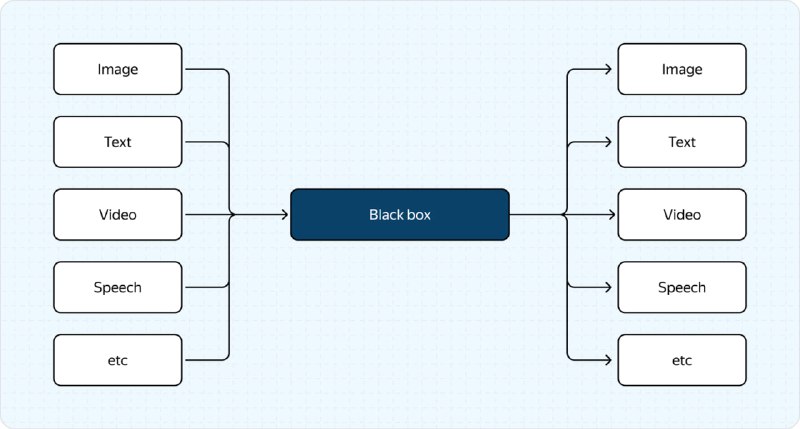
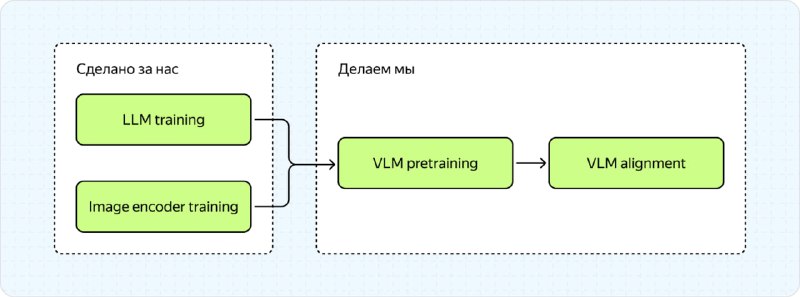
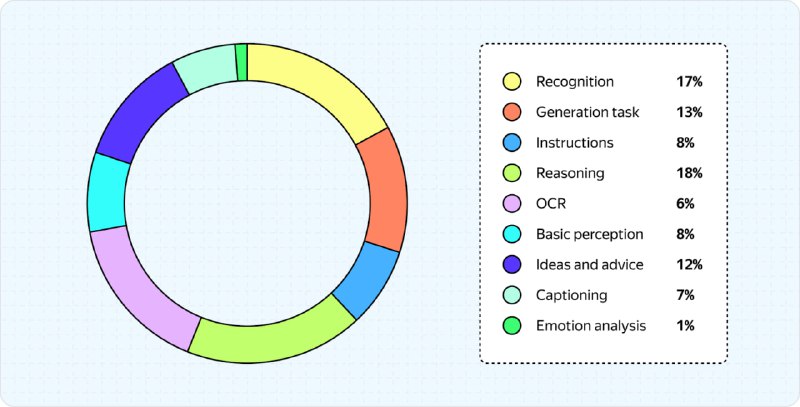
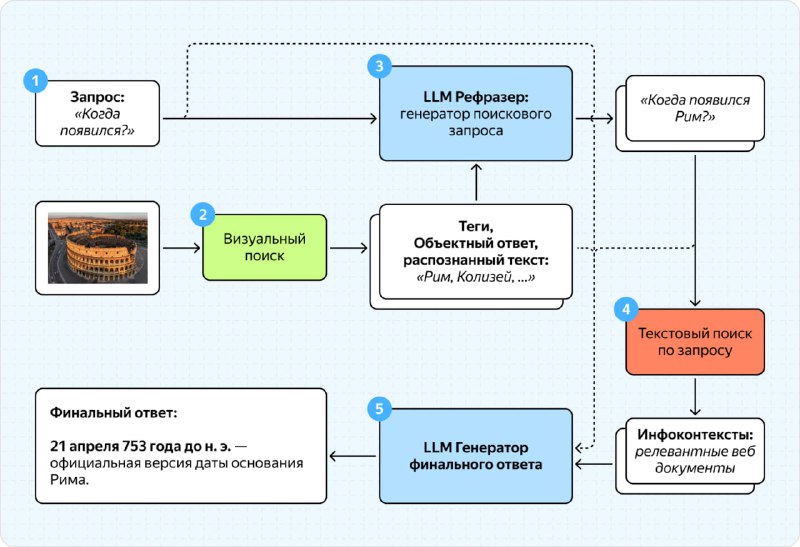
В своей статье на Хабре ML-разработчик Яндекса детально описывает, что представляют собой визуально-текстовые мультимодальные модели. Он аскрывает их архитектуру, состоящую из LLM, картиночного энкодера и адаптера, а также процесс обучения.
Кроме того, автор рассказывает про эволюцию Нейро: от предыдущей LLM-версии к новой VLM. Это позволяет понять, как изменился процесс обработки запросов и почему новая версия эффективнее.
Интересный инсайд: Яндекс использует instruct-based pretrain с несколькими миллионами семплов и активно работает над interleaved pretrain для дальнейшего улучшения качества модели.
▪️Статья на Хабре
@machinelearning_interview
В своей статье на Хабре ML-разработчик Яндекса детально описывает, что представляют собой визуально-текстовые мультимодальные модели. Он аскрывает их архитектуру, состоящую из LLM, картиночного энкодера и адаптера, а также процесс обучения.
Кроме того, автор рассказывает про эволюцию Нейро: от предыдущей LLM-версии к новой VLM. Это позволяет понять, как изменился процесс обработки запросов и почему новая версия эффективнее.
Интересный инсайд: Яндекс использует instruct-based pretrain с несколькими миллионами семплов и активно работает над interleaved pretrain для дальнейшего улучшения качества модели.
▪️Статья на Хабре
@machinelearning_interview
❤🔥10❤7🔥6
tgoop.com/machinelearning_interview/1236
Create:
Last Update:
Last Update:
📌 Яндекс добавил в Нейро новую мультимодальную VLM для поиска по картинкам
В своей статье на Хабре ML-разработчик Яндекса детально описывает, что представляют собой визуально-текстовые мультимодальные модели. Он аскрывает их архитектуру, состоящую из LLM, картиночного энкодера и адаптера, а также процесс обучения.
Кроме того, автор рассказывает про эволюцию Нейро: от предыдущей LLM-версии к новой VLM. Это позволяет понять, как изменился процесс обработки запросов и почему новая версия эффективнее.
Интересный инсайд: Яндекс использует instruct-based pretrain с несколькими миллионами семплов и активно работает над interleaved pretrain для дальнейшего улучшения качества модели.
▪️Статья на Хабре
@machinelearning_interview
В своей статье на Хабре ML-разработчик Яндекса детально описывает, что представляют собой визуально-текстовые мультимодальные модели. Он аскрывает их архитектуру, состоящую из LLM, картиночного энкодера и адаптера, а также процесс обучения.
Кроме того, автор рассказывает про эволюцию Нейро: от предыдущей LLM-версии к новой VLM. Это позволяет понять, как изменился процесс обработки запросов и почему новая версия эффективнее.
Интересный инсайд: Яндекс использует instruct-based pretrain с несколькими миллионами семплов и активно работает над interleaved pretrain для дальнейшего улучшения качества модели.
▪️Статья на Хабре
@machinelearning_interview
BY Machine learning Interview
Share with your friend now:
tgoop.com/machinelearning_interview/1236