🌟 Малые языковые модели: обзор, измерения и выводы.
Исследование, проведенное Университетом Кембриджа, Пекинским университетом почты и телекоммуникаций о малых языковых моделях, опубликованных в открытом доступе в период с 2022-2024 гг.
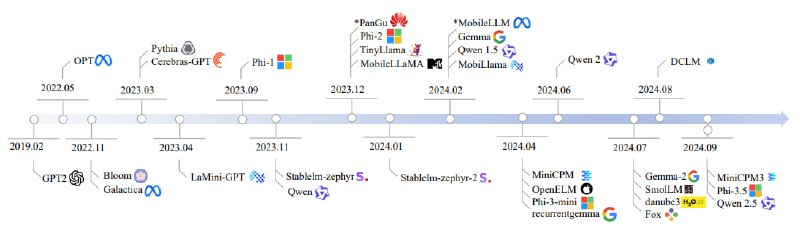
Авторами были проанализированы 59 современных открытых SLM, их архитектуру, используемые наборы данных для обучения и алгоритмы. Целевая группа состояла из моделей с 100M–5B параметрами, построенных на архитектуре декодера-трансформера, которые подходят для устройств от носимых гаджетов до смартфонов и планшетов.
Выводы, к которым пришли авторы:
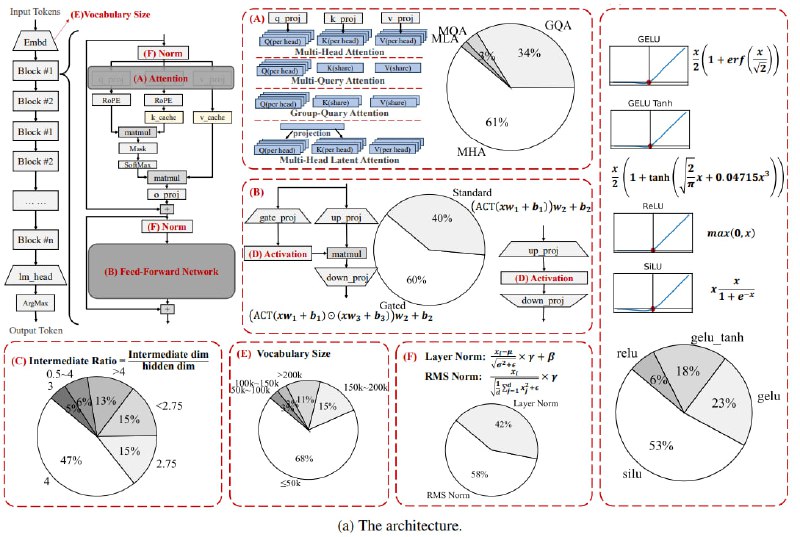
Архитектура SLM🟢Наблюдается переход от Multi-Head Attention (MHA) к Group-Query Attention (GQA) для повышения эффективности.
🟢Gated FFN с активацией SiLU и промежуточным соотношением 2-8 становится все более популярным выбором.
🟢Большинство моделей используют RMS-нормализацию и размер словаря более 50 тыс. токенов.
🟢Инновации в архитектуре пока ограничены.
Наборы данных для обучения🟢The Pile был наиболее часто используемым набором данных, но в последнее время выбор стал более разнообразным, все чаще используются RefinedWeb и RedPajama.
🟢Современные SLM обучаются на значительно большем количестве токенов (обычно >1.5T), чем предполагает
закон Chinchilla, что указывает на их «переобучение» для повышения производительности на устройствах с ограниченными ресурсами.
Алгоритмы обучения🟠Чаще используются новые методы: Maximal Update Parameterization (µP), Knowledge Distillation и Two Stage Pre-training Strategy для повышения стабильности обучения и эффективности переноса знаний.
Возможности SLM🟠За период с 2022 по 2024 год SLM показали значительное повышение производительности в разных задачах обработки естественного языка, превзойдя серию LLM LLaMA-7B.
🟠Семейство моделей Phi имеет самые высокие показатели точности, соперничая с LLaMA 3.1 8B.
🟠SLM, обученные на общедоступных датасетах, сокращают разрыв с моделями, обученными на закрытых данных, в задачах, связанных со здравым смыслом.
Контекстное обучение🟢Большинство SLM обладают способностью к контекстному обучению, хотя она зависит от задачи.
🟢Более крупные модели из SLM более восприимчивы к контекстному обучению.
Latency и потребление VRAM🟢Помимо размера модели, на задержку влияет и архитектура: количество слоев, ширина FFN, размер словаря и совместное использование параметров.
🟢Влияние архитектуры модели на скорость вывода более значительно на этапе предварительной обработки (prefill), чем на этапе декодирования.
🟢Использование памяти во время выполнения обычно линейно коррелирует с количеством параметров модели.
Влияние квантования и оборудования🟠Преимущества квантования на этапе декодирования больше, чем на этапе предварительной обработки.
🟠Графические процессоры демонстрируют еще большее преимущество перед центральными процессорами на этапе предварительной обработки.
🟡Arxiv🖥GitHub@ai_machinelearning_big_data#AI #ML #SLM #Paper #Arxiv