tgoop.com/machinelearning_interview/1206
Last Update:
Llama 3.1-Nemotron-51B-Instruct основана на Llama 3.1-70B и предназначена для NLP-задач генерации текста, чата, рассуждения и обобщения. Мультиязычность наследована от родительская модель. Llama 3.1-Nemotron-51B-Instruct также умеет обрабатывать языки программирования.
Архитектура модели построена с использованием методологии Neural Architecture Search (NAS) и блочной дистилляции.
NAS позволяет отобрать наиболее эффективные блоки трансформера для каждого слоя модели, а блочная дистилляция обеспечивает перенос знаний от исходной модели Llama 3.1-70B к более компактной Llama 3.1-Nemotron-51B-Instruct.
Полученная архитектура имеет нерегулярную структуру блоков с уменьшенным количеством операций внимания и полносвязных слоев, что существенно снижает вычислительную сложность и объем используемой памяти.
В процессе обучения модели использовались бенчмаркиMT-Bench и MMLU. Тестирование проводилось на задачах генерации текста, перевода и ответов на вопросы.
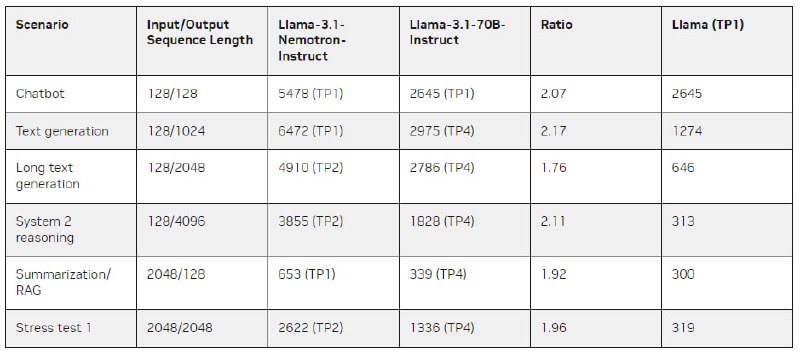
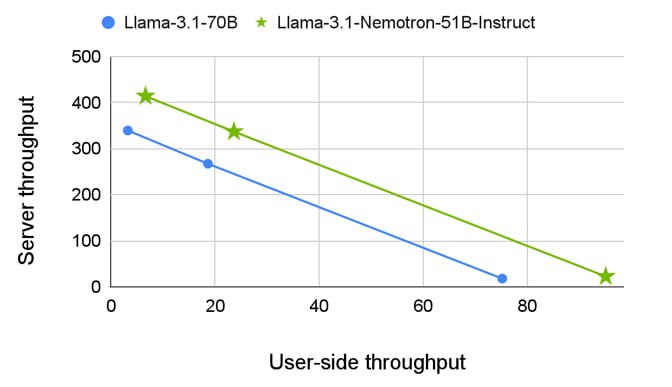
Результаты показали, что инференс Llama 3.1-Nemotron-51B-Instruct в 2.2 раза быстрее "родительской" модели (Llama 3.1-70B) при сохранении практически той же точности.
Благодаря сниженным требованиям к памяти, модель может обрабатывать в 4 раза большие объемы данных на одном GPU.
import torch
import transformers
model_id = "nvidia/Llama-3_1-Nemotron-51B-Instruct"
model_kwargs = {"torch_dtype": torch.bfloat16, "trust_remote_code": True, "device_map": "auto"}
tokenizer = transformers.AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token_id = tokenizer.eos_token_id
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
tokenizer=tokenizer,
max_new_tokens=20,
**model_kwargs
)
print(pipeline([{"role": "user", "content": "Hey how are you?"}]))
@ai_machinelearning_big_data
#AI #ML #LLM #Nemotron