tgoop.com/machinelearning_interview/1197
Last Update:
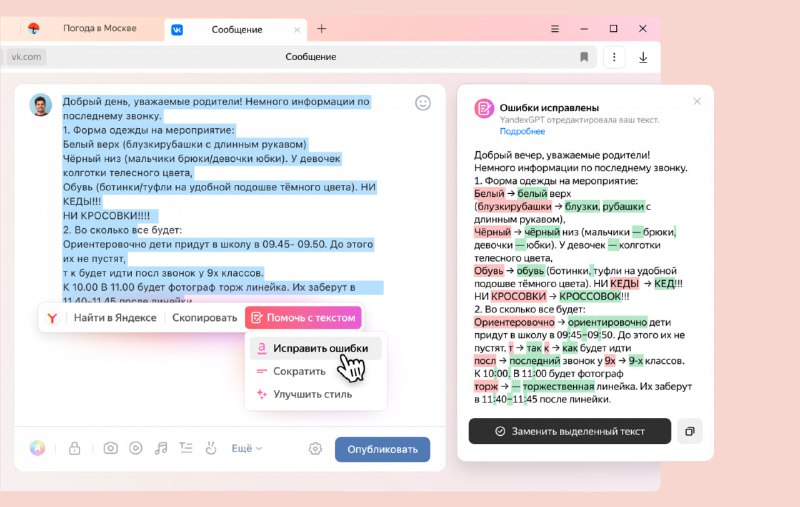
🛠 Эксперименты с обучением моделей для нейроредактора в Яндекс Браузере
Команда разработки доработала предыдущее решение, что в итоге привело к созданию отдельного инструмента на основе языковой модели YandexGPT. Он помогает пользователям создавать тексты с нуля и улучшать готовые прямо в браузере — например, исправлять ошибки и переписывать в определенном стиле и формате.
Для офлайн-метрик использовалась диффалка, написанная на Go. Диффалка работает на основе алгоритма поиска наибольшей общей подпоследовательности (LCS): ищутся наидлиннейшие общие подпоследовательности между версиями текста. Это позволило подсчитывать количество ошибок, которые модель не исправляет, сравнивая вывод модели с текстом, отредактированным человеком, и проверять гипотезы о качестве, экономя время.
Эксперименты (переход к Encoder-Decoder, curriculum learning, предобучение) дали ускорение в 2 раза и +10% качества на открытых датасетах.
Раньше при нейроредактировании модель могла легко удалить или добавить лишние спецсимволы, что приводило к непредсказуемым результатам. Теперь, с внедрением полноценной поддержки Маркдауна, эта проблема устранена. Для обеспечения корректной обработки разметки применялся подход восстановления: прогон текста через модель, ручное восстановление пропавшей разметки и переобучение модели. В итоге достигнуто сохранение разметки 1:1 в модели исправления ошибок.
📝 Хабр
@machinelearning_interview
BY Machine learning Interview
Share with your friend now:
tgoop.com/machinelearning_interview/1197