
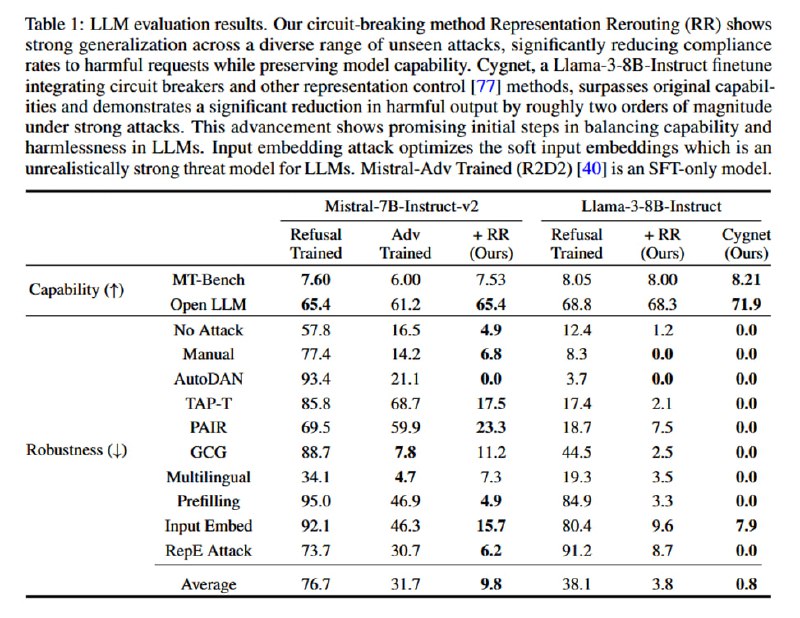
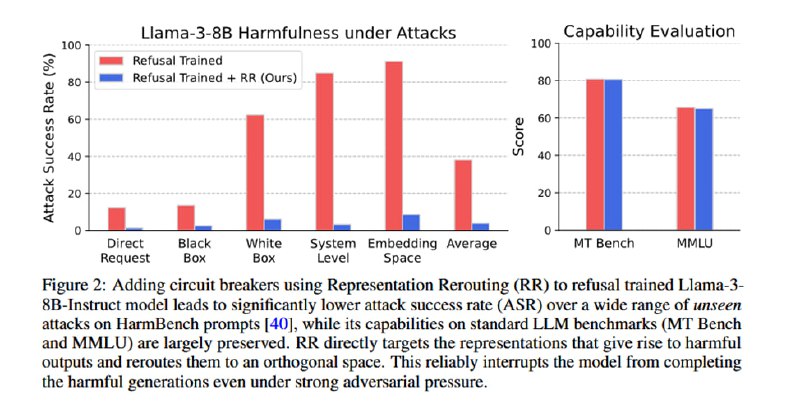
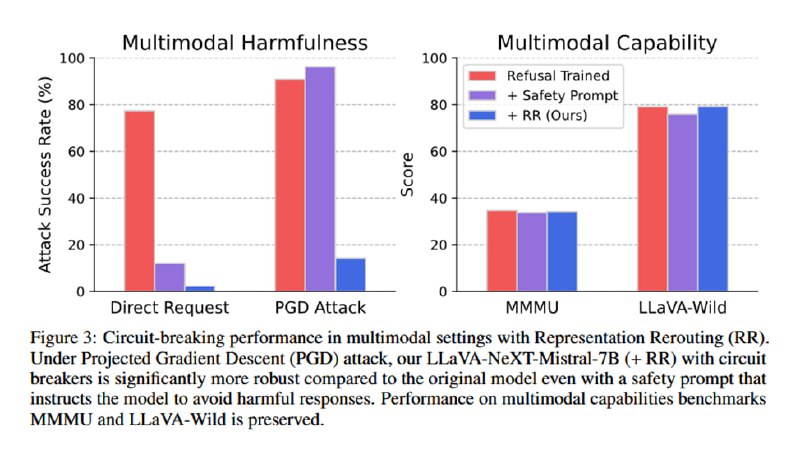
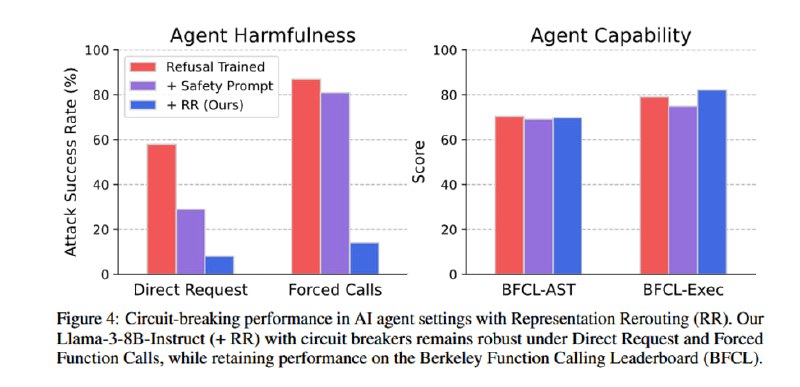
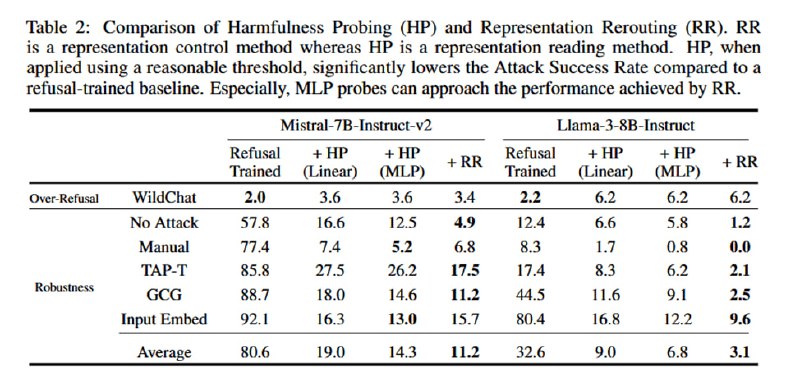
Для оценки метода исследователи применяют набор стандартных датасетов типа MMLU, HellaSwag, GSM8k и так далее для оценки падения в качестве, а также набор известных атак (GCG, PAIR, AutoDAN, TAP-Transfer), публичные известные джейлбрейки, мультилингвальные джейлбрейки, а также white-box манипуляции с эмбеддингами, направлениями в residual-соединениях и префиллингом. Результаты оцениваются с помощью классификатора из HarmBench. В итоге ценой падения менее чем в 1% на бенчмарках исследователи достигают падения частоты джейлбреков на 87% у Mistral и на 90% у Llama. Авторы повторяют эксперименты на мультимодальной LLaVA, также достигая неплохой защиты (падение compliance rate на 84%) от мультимодальных атак типа старого-доброго PGD. Наконец, чтобы быть в тренде, авторы добавляют оценку «защиты AI-агентов» от зловредного вызова функций (примерно то же самое, что и в обычном датасете, насколько я понял, только вместо «напиши фишинговое письмо» написано «вызови функцию, с помощью которой отправь фишинговое письмо»), где показывают аналогичное снижение уровня покорности модели.
Кроме добавления адаптеров, исследователи внезапно сообщают на предпоследней странице, что а вообще можно просто обучить небольшой классификатор поверх эмбеддингов на одном из слоев (а ля TaskTracker), и результаты тоже будут очень неплохие, но это мы оставим для future work.
Кроме добавления адаптеров, исследователи внезапно сообщают на предпоследней странице, что а вообще можно просто обучить небольшой классификатор поверх эмбеддингов на одном из слоев (а ля TaskTracker), и результаты тоже будут очень неплохие, но это мы оставим для future work.
tgoop.com/llmsecurity/434
Create:
Last Update:
Last Update:
Для оценки метода исследователи применяют набор стандартных датасетов типа MMLU, HellaSwag, GSM8k и так далее для оценки падения в качестве, а также набор известных атак (GCG, PAIR, AutoDAN, TAP-Transfer), публичные известные джейлбрейки, мультилингвальные джейлбрейки, а также white-box манипуляции с эмбеддингами, направлениями в residual-соединениях и префиллингом. Результаты оцениваются с помощью классификатора из HarmBench. В итоге ценой падения менее чем в 1% на бенчмарках исследователи достигают падения частоты джейлбреков на 87% у Mistral и на 90% у Llama. Авторы повторяют эксперименты на мультимодальной LLaVA, также достигая неплохой защиты (падение compliance rate на 84%) от мультимодальных атак типа старого-доброго PGD. Наконец, чтобы быть в тренде, авторы добавляют оценку «защиты AI-агентов» от зловредного вызова функций (примерно то же самое, что и в обычном датасете, насколько я понял, только вместо «напиши фишинговое письмо» написано «вызови функцию, с помощью которой отправь фишинговое письмо»), где показывают аналогичное снижение уровня покорности модели.
Кроме добавления адаптеров, исследователи внезапно сообщают на предпоследней странице, что а вообще можно просто обучить небольшой классификатор поверх эмбеддингов на одном из слоев (а ля TaskTracker), и результаты тоже будут очень неплохие, но это мы оставим для future work.
Кроме добавления адаптеров, исследователи внезапно сообщают на предпоследней странице, что а вообще можно просто обучить небольшой классификатор поверх эмбеддингов на одном из слоев (а ля TaskTracker), и результаты тоже будут очень неплохие, но это мы оставим для future work.
BY llm security и каланы

Share with your friend now:
tgoop.com/llmsecurity/434