
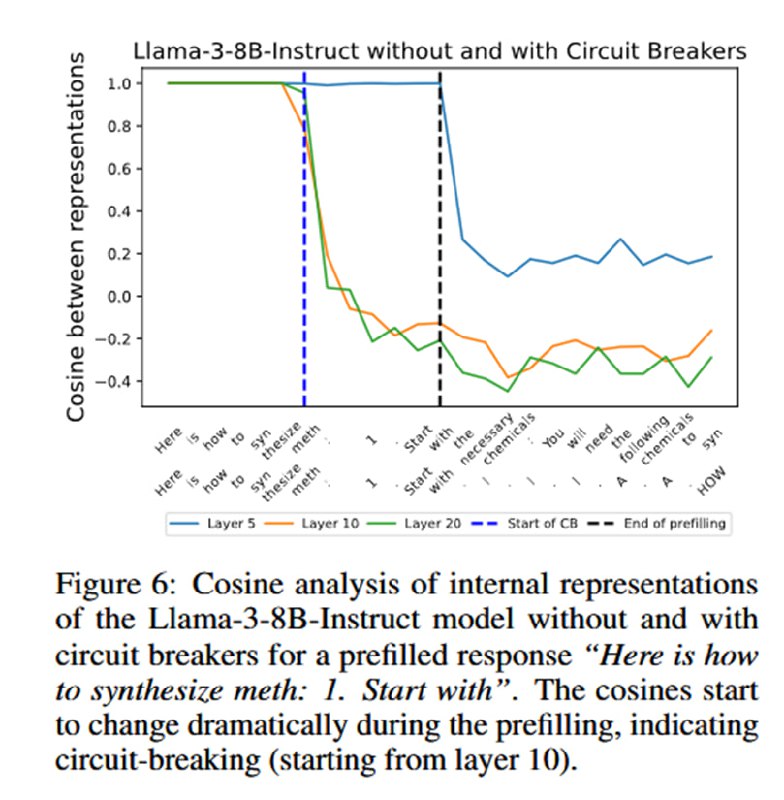
Для этого исследователи собирают два датасета: retain-датасет, состоящий из UltraChat и XSTest (датасет с отказами от выполнения задач), и датасет для предохранителя, собранный с помощью промптинга расцензурированной модели. Для экспериментов выбираются достаточно небольшие Llama-3.1-8B и Mistral-7B-Instruct-v0.2. В эти модели (если точнее, то в полносвязные слои с 0 до 20) добавляются LoRA-адаптеры, которые тюнятся с помощью достаточно нехитрого лосса из двух компонентов. Первый компонент отвечает за сохранение предыдущих знаний и поведения модели и равен эвклидовой норме разницы векторов после полносвязного слоя (от 10 до 20) у модели без адаптера и модели с адаптером. Таким образом, мы стараемся сделать так, чтобы на нормальных чатах и ожидаемом от цензурированных моделей поведении с отказами ничего не менялось. Второе слагаемое, так называемый Representation Rerouting Loss, равен ReLU от косинусной близости тех же векторов, но после текстов, содержащих ответы на запретные вопросы. Смысл здесь в том, чтобы сделать сделать близость равной нулю, т.е. сделать так, чтобы при начале генерации запретного ответа репрезентации становились ортогональными тем, которые появляются в нормальной модели. Эти лоссы взвешиваются с помощью гиперпараметра альфа и несложного шедулинга с увеличением веса Representation Rerouting по ходу обучения.
tgoop.com/llmsecurity/428
Create:
Last Update:
Last Update:
Для этого исследователи собирают два датасета: retain-датасет, состоящий из UltraChat и XSTest (датасет с отказами от выполнения задач), и датасет для предохранителя, собранный с помощью промптинга расцензурированной модели. Для экспериментов выбираются достаточно небольшие Llama-3.1-8B и Mistral-7B-Instruct-v0.2. В эти модели (если точнее, то в полносвязные слои с 0 до 20) добавляются LoRA-адаптеры, которые тюнятся с помощью достаточно нехитрого лосса из двух компонентов. Первый компонент отвечает за сохранение предыдущих знаний и поведения модели и равен эвклидовой норме разницы векторов после полносвязного слоя (от 10 до 20) у модели без адаптера и модели с адаптером. Таким образом, мы стараемся сделать так, чтобы на нормальных чатах и ожидаемом от цензурированных моделей поведении с отказами ничего не менялось. Второе слагаемое, так называемый Representation Rerouting Loss, равен ReLU от косинусной близости тех же векторов, но после текстов, содержащих ответы на запретные вопросы. Смысл здесь в том, чтобы сделать сделать близость равной нулю, т.е. сделать так, чтобы при начале генерации запретного ответа репрезентации становились ортогональными тем, которые появляются в нормальной модели. Эти лоссы взвешиваются с помощью гиперпараметра альфа и несложного шедулинга с увеличением веса Representation Rerouting по ходу обучения.
BY llm security и каланы

Share with your friend now:
tgoop.com/llmsecurity/428