
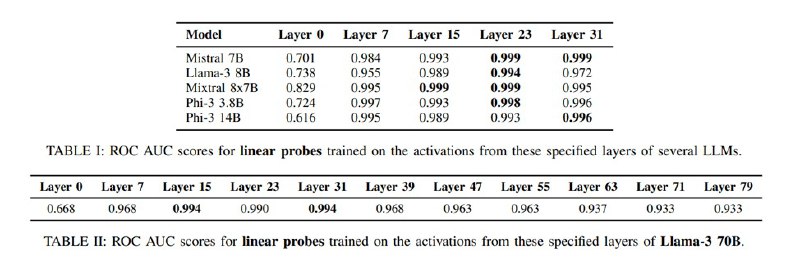
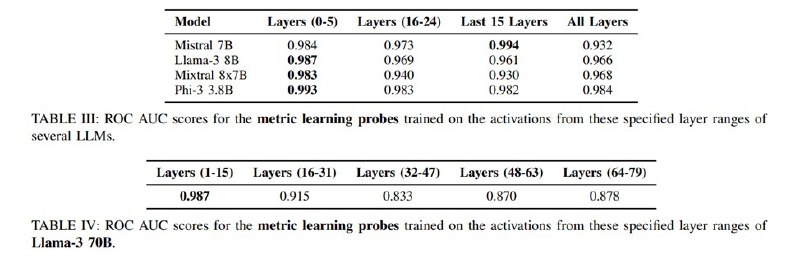
Все это тестируется на нескольких датасетах: валидационная часть SQuAD, HotPotQA, вариациях с несколькими основными задачами и разные задачи – Code Alpaca, зловредные задачи из многострадального AdvBench и других датасетов с джейлбрейками и даже джейлбрейки сгенерированные разными подходами вроде PAIR под заданные модели. Логрег (как это часто бывает на практике) выигрывает в сравнении, показывая ROC-AUC на уровне 0,999 для некоторых моделей с лучшими результатами при использовании активаций с более глубоких слоев.
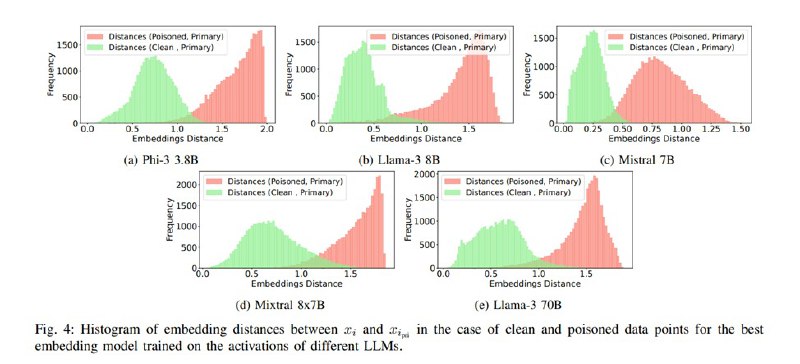
Статья интересная, есть много дополнительных иллюстраций, измерений и занятных наблюдений. Самое важное, однако, как мне кажется, отмечается в разделе про ограничения метода: хотя по метрикам метод «вроде работает», что именно детектируется на базе дельт активаций, совершенно непонятно: то ли это семантика наличия двух задач, то ли это какие-то соответствующие этому синтаксические явления, то ли еще что-то. Исследователи отмечают, что метод работает лучше, когда блоки данных короткие и когда вредоносная инструкция находится ближе к концу, кроме того, как мы помним, синтетика включала в себя отсутствие разделителей и прочее. По опыту, он действительно триггерится на внезапные разделители и поломанный синтаксис. Таким образом, хотя сам подход (работа в пространстве активаций, а не токенов для обнаружения неожиданного поведения) кажется многообещающим, тот факт, что мы понятие не имеем, что там кодируется (спутанность направлений, полисемантичность), может очень сильно затруднять как общие попытки разобраться в функционировании LLM, так и в оценке применимости конкретных методов.
Статья интересная, есть много дополнительных иллюстраций, измерений и занятных наблюдений. Самое важное, однако, как мне кажется, отмечается в разделе про ограничения метода: хотя по метрикам метод «вроде работает», что именно детектируется на базе дельт активаций, совершенно непонятно: то ли это семантика наличия двух задач, то ли это какие-то соответствующие этому синтаксические явления, то ли еще что-то. Исследователи отмечают, что метод работает лучше, когда блоки данных короткие и когда вредоносная инструкция находится ближе к концу, кроме того, как мы помним, синтетика включала в себя отсутствие разделителей и прочее. По опыту, он действительно триггерится на внезапные разделители и поломанный синтаксис. Таким образом, хотя сам подход (работа в пространстве активаций, а не токенов для обнаружения неожиданного поведения) кажется многообещающим, тот факт, что мы понятие не имеем, что там кодируется (спутанность направлений, полисемантичность), может очень сильно затруднять как общие попытки разобраться в функционировании LLM, так и в оценке применимости конкретных методов.
tgoop.com/llmsecurity/405
Create:
Last Update:
Last Update:
Все это тестируется на нескольких датасетах: валидационная часть SQuAD, HotPotQA, вариациях с несколькими основными задачами и разные задачи – Code Alpaca, зловредные задачи из многострадального AdvBench и других датасетов с джейлбрейками и даже джейлбрейки сгенерированные разными подходами вроде PAIR под заданные модели. Логрег (как это часто бывает на практике) выигрывает в сравнении, показывая ROC-AUC на уровне 0,999 для некоторых моделей с лучшими результатами при использовании активаций с более глубоких слоев.
Статья интересная, есть много дополнительных иллюстраций, измерений и занятных наблюдений. Самое важное, однако, как мне кажется, отмечается в разделе про ограничения метода: хотя по метрикам метод «вроде работает», что именно детектируется на базе дельт активаций, совершенно непонятно: то ли это семантика наличия двух задач, то ли это какие-то соответствующие этому синтаксические явления, то ли еще что-то. Исследователи отмечают, что метод работает лучше, когда блоки данных короткие и когда вредоносная инструкция находится ближе к концу, кроме того, как мы помним, синтетика включала в себя отсутствие разделителей и прочее. По опыту, он действительно триггерится на внезапные разделители и поломанный синтаксис. Таким образом, хотя сам подход (работа в пространстве активаций, а не токенов для обнаружения неожиданного поведения) кажется многообещающим, тот факт, что мы понятие не имеем, что там кодируется (спутанность направлений, полисемантичность), может очень сильно затруднять как общие попытки разобраться в функционировании LLM, так и в оценке применимости конкретных методов.
Статья интересная, есть много дополнительных иллюстраций, измерений и занятных наблюдений. Самое важное, однако, как мне кажется, отмечается в разделе про ограничения метода: хотя по метрикам метод «вроде работает», что именно детектируется на базе дельт активаций, совершенно непонятно: то ли это семантика наличия двух задач, то ли это какие-то соответствующие этому синтаксические явления, то ли еще что-то. Исследователи отмечают, что метод работает лучше, когда блоки данных короткие и когда вредоносная инструкция находится ближе к концу, кроме того, как мы помним, синтетика включала в себя отсутствие разделителей и прочее. По опыту, он действительно триггерится на внезапные разделители и поломанный синтаксис. Таким образом, хотя сам подход (работа в пространстве активаций, а не токенов для обнаружения неожиданного поведения) кажется многообещающим, тот факт, что мы понятие не имеем, что там кодируется (спутанность направлений, полисемантичность), может очень сильно затруднять как общие попытки разобраться в функционировании LLM, так и в оценке применимости конкретных методов.
BY llm security и каланы
Share with your friend now:
tgoop.com/llmsecurity/405