
Для реализации метода собирается датасет активаций разных LLM на разных слоях. Исследователи берут задачу QA и несколько синтетических задач из датасета SEP (суммаризацию, перевод, извлечение ключевых слов), в качестве источника текстов берут SQuAD. В качестве внедренных задач используются инъекции, сгенерированные GPT-4 – от тонких подводок до набранных капсом инструкций с разделителями. Эти инструкции рандомно вставляются в начало, конец и середину текста.
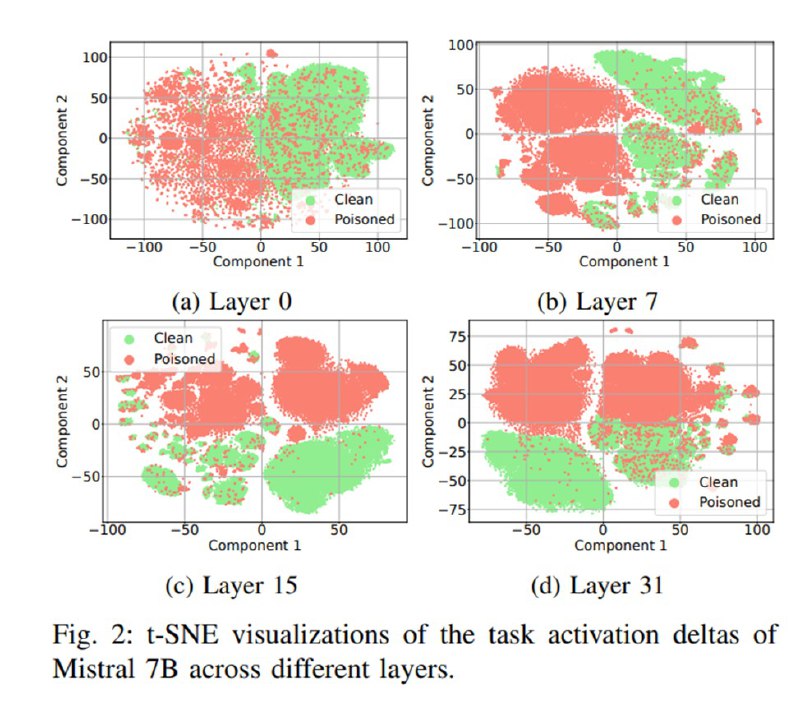
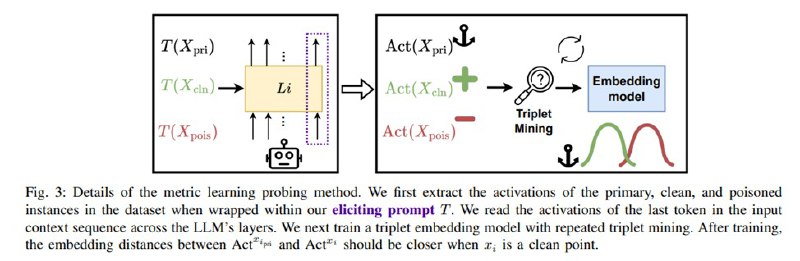
Собственно, активации собираются с каждого слоя после обработки LLM специальной затравки, которая фокусирует ее внимание на основной задаче (см. скриншот), а также после обработки всего текста, включая блоки данных с внедренной задачей и без нее (чистый сабсет). Нелинейное снижение размерности (t-SNE) показывает, что наборы данных относительно разделимы в пространстве дельт активаций. Для непосредственно детекта сдвига используются две формулировки задачи: metric learning (контрастивный подход) и логистическая регрессия над дельтами изначальной и финальной активации. Для контрастивного подхода используется triplet loss на тройках (активация после основной задачи, активация после чистого блока, активация после блока с внедренной задачей), оптимизируется он на некоторой многослойной сети с одномерными свертками.
Собственно, активации собираются с каждого слоя после обработки LLM специальной затравки, которая фокусирует ее внимание на основной задаче (см. скриншот), а также после обработки всего текста, включая блоки данных с внедренной задачей и без нее (чистый сабсет). Нелинейное снижение размерности (t-SNE) показывает, что наборы данных относительно разделимы в пространстве дельт активаций. Для непосредственно детекта сдвига используются две формулировки задачи: metric learning (контрастивный подход) и логистическая регрессия над дельтами изначальной и финальной активации. Для контрастивного подхода используется triplet loss на тройках (активация после основной задачи, активация после чистого блока, активация после блока с внедренной задачей), оптимизируется он на некоторой многослойной сети с одномерными свертками.
tgoop.com/llmsecurity/400
Create:
Last Update:
Last Update:
Для реализации метода собирается датасет активаций разных LLM на разных слоях. Исследователи берут задачу QA и несколько синтетических задач из датасета SEP (суммаризацию, перевод, извлечение ключевых слов), в качестве источника текстов берут SQuAD. В качестве внедренных задач используются инъекции, сгенерированные GPT-4 – от тонких подводок до набранных капсом инструкций с разделителями. Эти инструкции рандомно вставляются в начало, конец и середину текста.
Собственно, активации собираются с каждого слоя после обработки LLM специальной затравки, которая фокусирует ее внимание на основной задаче (см. скриншот), а также после обработки всего текста, включая блоки данных с внедренной задачей и без нее (чистый сабсет). Нелинейное снижение размерности (t-SNE) показывает, что наборы данных относительно разделимы в пространстве дельт активаций. Для непосредственно детекта сдвига используются две формулировки задачи: metric learning (контрастивный подход) и логистическая регрессия над дельтами изначальной и финальной активации. Для контрастивного подхода используется triplet loss на тройках (активация после основной задачи, активация после чистого блока, активация после блока с внедренной задачей), оптимизируется он на некоторой многослойной сети с одномерными свертками.
Собственно, активации собираются с каждого слоя после обработки LLM специальной затравки, которая фокусирует ее внимание на основной задаче (см. скриншот), а также после обработки всего текста, включая блоки данных с внедренной задачей и без нее (чистый сабсет). Нелинейное снижение размерности (t-SNE) показывает, что наборы данных относительно разделимы в пространстве дельт активаций. Для непосредственно детекта сдвига используются две формулировки задачи: metric learning (контрастивный подход) и логистическая регрессия над дельтами изначальной и финальной активации. Для контрастивного подхода используется triplet loss на тройках (активация после основной задачи, активация после чистого блока, активация после блока с внедренной задачей), оптимизируется он на некоторой многослойной сети с одномерными свертками.
BY llm security и каланы


Share with your friend now:
tgoop.com/llmsecurity/400