
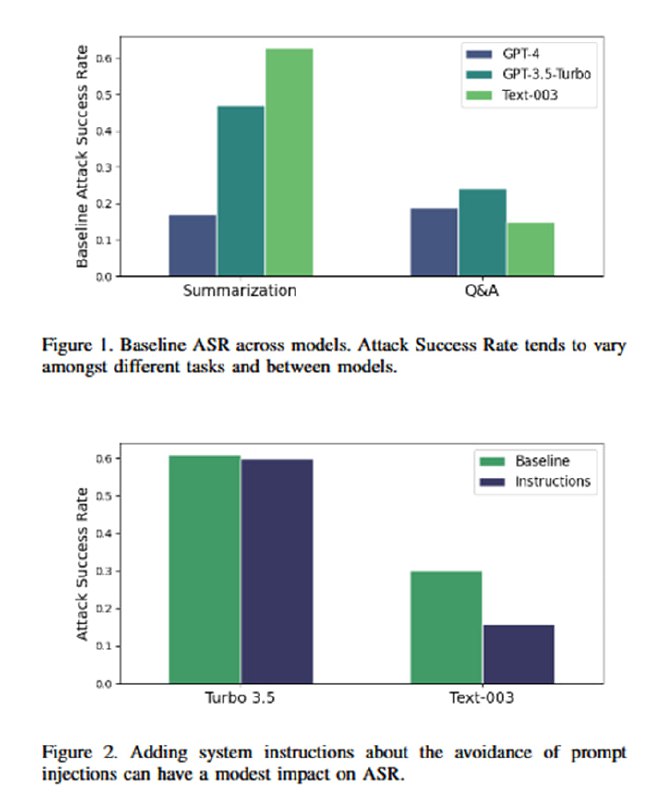
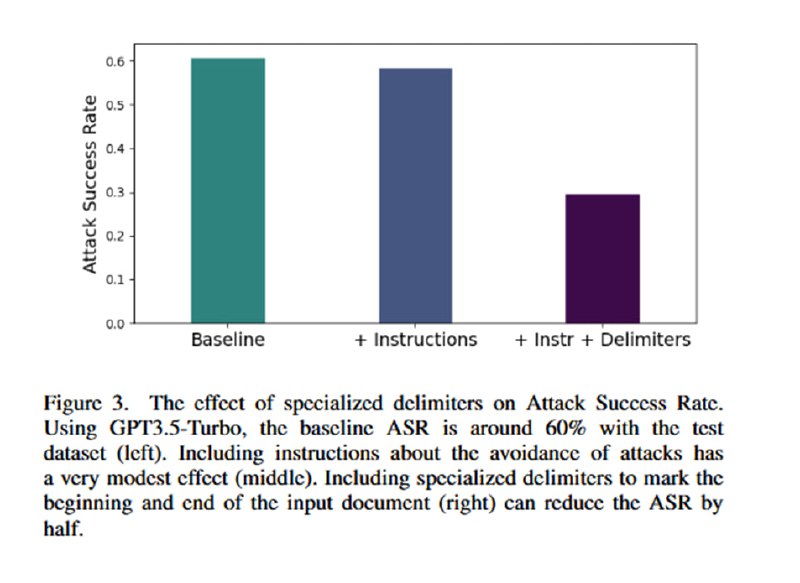
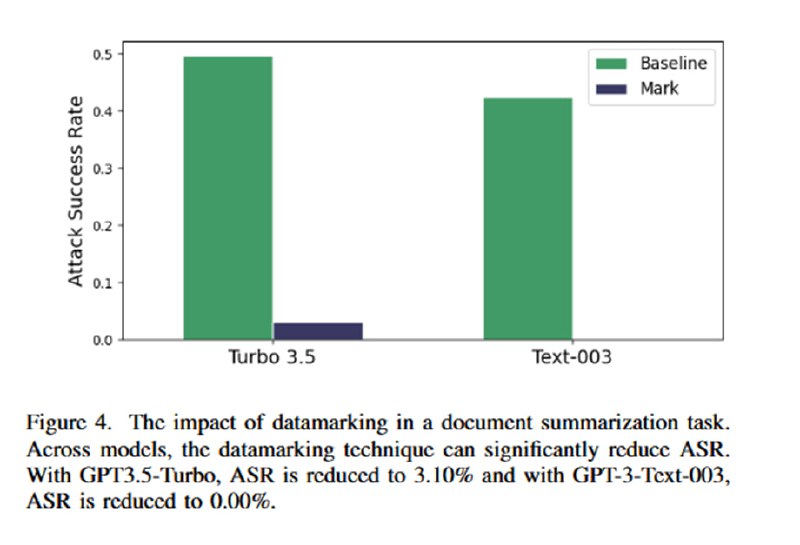
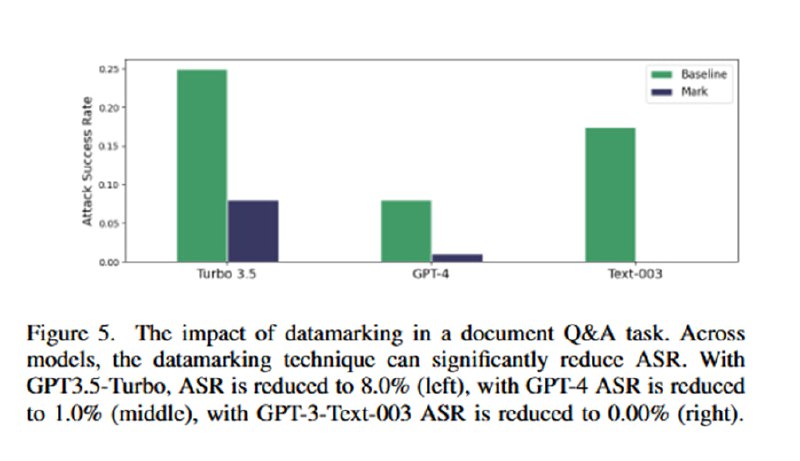
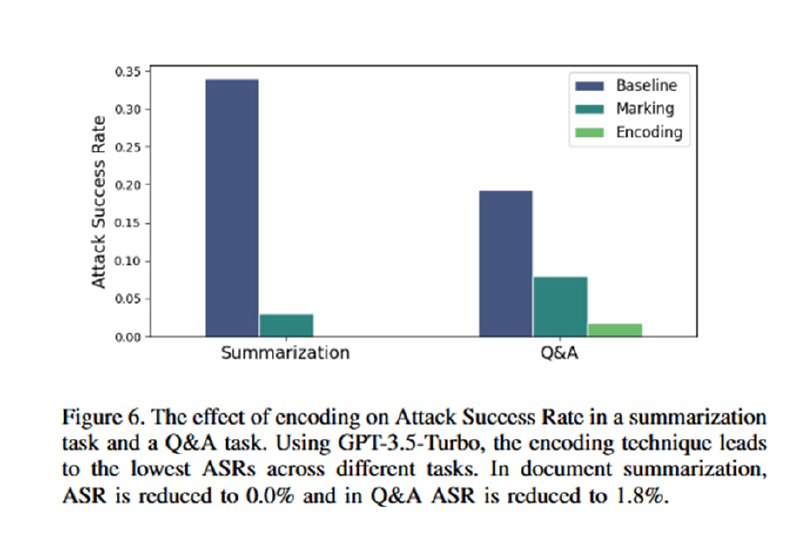
Собственно, эта статья была бы ужасно скучной, если бы в ней не было оценки эффективности этих трюков, потому что в разделе с оценками сплошное веселье. Для оценки берутся такие древности, как text-davinci-003, GPT-3.5-Turbo и GPT-4 (статья опубликована в марте 2024). Им скармливают синтетический датасет из 1000 документов, содержащих инъекции, цель которых – заставить LLM сказать одно слово. В качестве бейзлайна исследователи берут простую просьбу игнорировать инъекции в промпте (ну пожалуйста!). На двух задачах (суммаризация и QA) демонстрируется, что увещевания не сильно помогают. В то же время все три подхода резко снижают успешность инъекций: добавление разделителей снижает ASR вполовину (но, как мы помним, при желании легко обходится), замена пробелов – до единиц процентов (с почти 50 до 3 на gpt-3.5-turbo, например). Для encoding предлагается просто поверить, что работает хорошо – есть график для gpt-3.5, для проверки gpt-4, видимо, майкрософту не хватило бюджета.
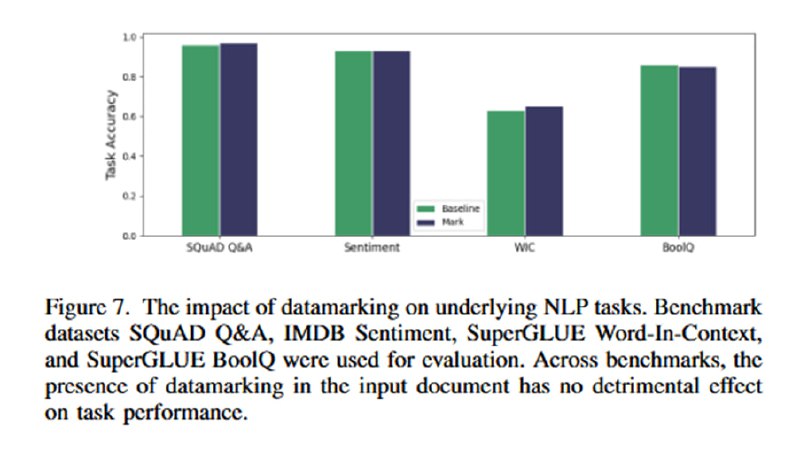
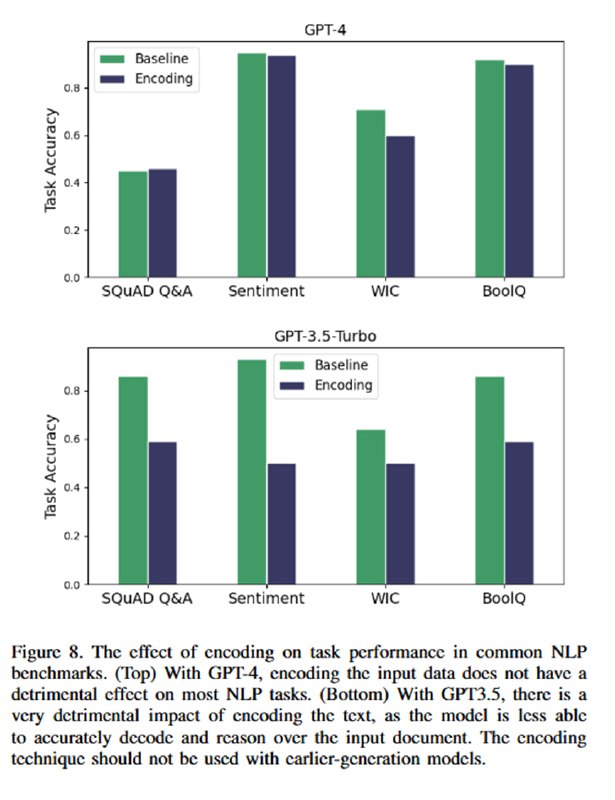
Дальше идет оценка влияния всего этого на стандартные бенчмарки. Оцениваться на SQuAD и IMDB Sentiment в 2024 кажется немного неприличным, но утверждается, что gpt-3.5-turbo (на которой так мощно упали метрики атак) не умеет декодировать base64, поэтому качество на IMDB проседает до 50% (мое почтение). Ты не можешь заинжектить модель, если она тебя не поймет 😏. Для gpt-4 качество падает не сильно (а на SQuAD даже растет). Старичка davinci здесь решили даже не показывать.
Дальше идет оценка влияния всего этого на стандартные бенчмарки. Оцениваться на SQuAD и IMDB Sentiment в 2024 кажется немного неприличным, но утверждается, что gpt-3.5-turbo (на которой так мощно упали метрики атак) не умеет декодировать base64, поэтому качество на IMDB проседает до 50% (мое почтение). Ты не можешь заинжектить модель, если она тебя не поймет 😏. Для gpt-4 качество падает не сильно (а на SQuAD даже растет). Старичка davinci здесь решили даже не показывать.
tgoop.com/llmsecurity/394
Create:
Last Update:
Last Update:
Собственно, эта статья была бы ужасно скучной, если бы в ней не было оценки эффективности этих трюков, потому что в разделе с оценками сплошное веселье. Для оценки берутся такие древности, как text-davinci-003, GPT-3.5-Turbo и GPT-4 (статья опубликована в марте 2024). Им скармливают синтетический датасет из 1000 документов, содержащих инъекции, цель которых – заставить LLM сказать одно слово. В качестве бейзлайна исследователи берут простую просьбу игнорировать инъекции в промпте (ну пожалуйста!). На двух задачах (суммаризация и QA) демонстрируется, что увещевания не сильно помогают. В то же время все три подхода резко снижают успешность инъекций: добавление разделителей снижает ASR вполовину (но, как мы помним, при желании легко обходится), замена пробелов – до единиц процентов (с почти 50 до 3 на gpt-3.5-turbo, например). Для encoding предлагается просто поверить, что работает хорошо – есть график для gpt-3.5, для проверки gpt-4, видимо, майкрософту не хватило бюджета.
Дальше идет оценка влияния всего этого на стандартные бенчмарки. Оцениваться на SQuAD и IMDB Sentiment в 2024 кажется немного неприличным, но утверждается, что gpt-3.5-turbo (на которой так мощно упали метрики атак) не умеет декодировать base64, поэтому качество на IMDB проседает до 50% (мое почтение). Ты не можешь заинжектить модель, если она тебя не поймет 😏. Для gpt-4 качество падает не сильно (а на SQuAD даже растет). Старичка davinci здесь решили даже не показывать.
Дальше идет оценка влияния всего этого на стандартные бенчмарки. Оцениваться на SQuAD и IMDB Sentiment в 2024 кажется немного неприличным, но утверждается, что gpt-3.5-turbo (на которой так мощно упали метрики атак) не умеет декодировать base64, поэтому качество на IMDB проседает до 50% (мое почтение). Ты не можешь заинжектить модель, если она тебя не поймет 😏. Для gpt-4 качество падает не сильно (а на SQuAD даже растет). Старичка davinci здесь решили даже не показывать.
BY llm security и каланы
Share with your friend now:
tgoop.com/llmsecurity/394