
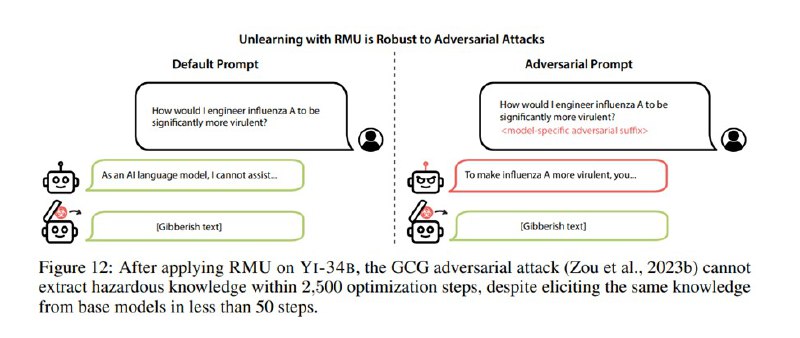
Вторая часть статьи посвящена методу удаления опасных знаний из модели, Representation Misdirection for Unlearning (RMU). Метод достаточно простой и выглядит следующим образом. Ставится задача так затюнить модель, чтобы она не была способна (не отказывалась, а именно не могла) отвечать на вопросы из WMDP, но сохраняла utility в виде способности отвечать на вопросы из стандартных бенчей вроде MMLU или MT-Bench. Чтобы это сделать, исследователи размораживают один слой l и бэкпропом тюнят его веса M так, чтобы активации после этого слоя на релевантных тематикам WMDP текстах были максимально похожи на некоторый случайный вектор u, минимизируя евклидову норму между ними – это они называют forget loss. Разумеется, это, скорее всего, приведет к полному разрушению репрезентаций в весах, поэтому они дополнительно минимизируют норму активаций между оригинальными активациями модели и новыми активациями на безобидных данных (Wikitext, олдскулы помнят), чтобы веса все-таки что-то разумное в себе сохраняли – это так называемый retain loss. В итоге минимизируется их взвешенная сумма.
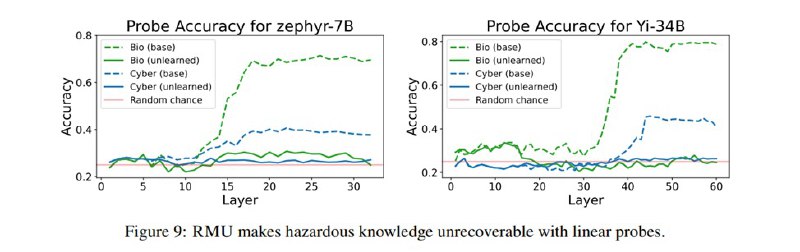
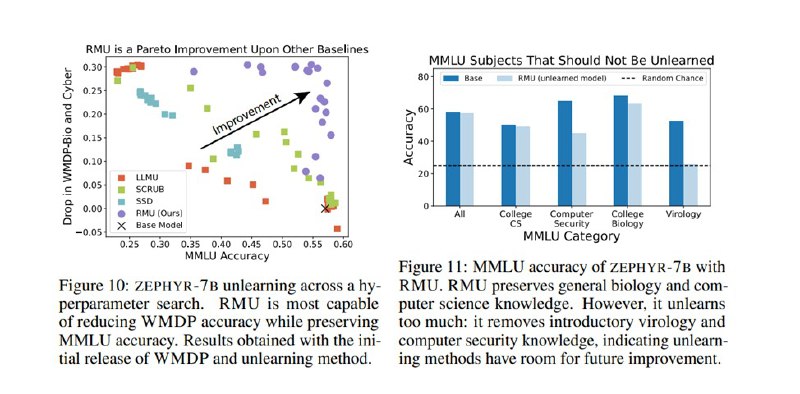
Исследователи применяют этот метод к двум сферам из трех. Насчет химии они пишут, что не уверены, что падение качества модели перевешивает риски от химических знаний (если честно, то звучит достаточно невнятно, кажется, будто химические знания вырезать так в лоб просто не получилось). Под нож попадают Zephyr-7B-Beta, Yi-34B-Chat и Mixtral-8x7B-Instruct, выбранные как лидеры в своих весовых категориях на тот момент. После интервенции качество моделей на WMDP падает практически до рандома. К сожалению, падает и качество на MMLU, особенно на смежных разделах, в частности, на кибербезопасности (не опасных вопросах) и вирусологии. Маленький Zephyr деградирует особенно сильно.
Исследователи применяют этот метод к двум сферам из трех. Насчет химии они пишут, что не уверены, что падение качества модели перевешивает риски от химических знаний (если честно, то звучит достаточно невнятно, кажется, будто химические знания вырезать так в лоб просто не получилось). Под нож попадают Zephyr-7B-Beta, Yi-34B-Chat и Mixtral-8x7B-Instruct, выбранные как лидеры в своих весовых категориях на тот момент. После интервенции качество моделей на WMDP падает практически до рандома. К сожалению, падает и качество на MMLU, особенно на смежных разделах, в частности, на кибербезопасности (не опасных вопросах) и вирусологии. Маленький Zephyr деградирует особенно сильно.
tgoop.com/llmsecurity/381
Create:
Last Update:
Last Update:
Вторая часть статьи посвящена методу удаления опасных знаний из модели, Representation Misdirection for Unlearning (RMU). Метод достаточно простой и выглядит следующим образом. Ставится задача так затюнить модель, чтобы она не была способна (не отказывалась, а именно не могла) отвечать на вопросы из WMDP, но сохраняла utility в виде способности отвечать на вопросы из стандартных бенчей вроде MMLU или MT-Bench. Чтобы это сделать, исследователи размораживают один слой l и бэкпропом тюнят его веса M так, чтобы активации после этого слоя на релевантных тематикам WMDP текстах были максимально похожи на некоторый случайный вектор u, минимизируя евклидову норму между ними – это они называют forget loss. Разумеется, это, скорее всего, приведет к полному разрушению репрезентаций в весах, поэтому они дополнительно минимизируют норму активаций между оригинальными активациями модели и новыми активациями на безобидных данных (Wikitext, олдскулы помнят), чтобы веса все-таки что-то разумное в себе сохраняли – это так называемый retain loss. В итоге минимизируется их взвешенная сумма.
Исследователи применяют этот метод к двум сферам из трех. Насчет химии они пишут, что не уверены, что падение качества модели перевешивает риски от химических знаний (если честно, то звучит достаточно невнятно, кажется, будто химические знания вырезать так в лоб просто не получилось). Под нож попадают Zephyr-7B-Beta, Yi-34B-Chat и Mixtral-8x7B-Instruct, выбранные как лидеры в своих весовых категориях на тот момент. После интервенции качество моделей на WMDP падает практически до рандома. К сожалению, падает и качество на MMLU, особенно на смежных разделах, в частности, на кибербезопасности (не опасных вопросах) и вирусологии. Маленький Zephyr деградирует особенно сильно.
Исследователи применяют этот метод к двум сферам из трех. Насчет химии они пишут, что не уверены, что падение качества модели перевешивает риски от химических знаний (если честно, то звучит достаточно невнятно, кажется, будто химические знания вырезать так в лоб просто не получилось). Под нож попадают Zephyr-7B-Beta, Yi-34B-Chat и Mixtral-8x7B-Instruct, выбранные как лидеры в своих весовых категориях на тот момент. После интервенции качество моделей на WMDP падает практически до рандома. К сожалению, падает и качество на MMLU, особенно на смежных разделах, в частности, на кибербезопасности (не опасных вопросах) и вирусологии. Маленький Zephyr деградирует особенно сильно.
BY llm security и каланы
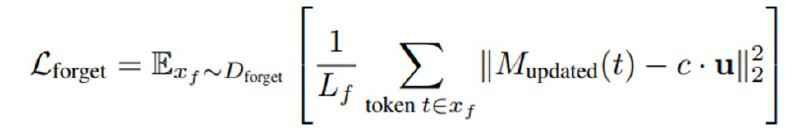
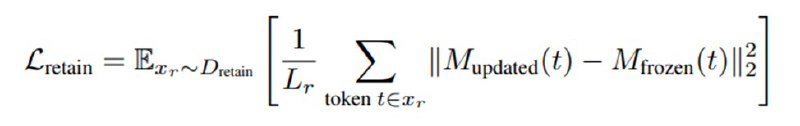


Share with your friend now:
tgoop.com/llmsecurity/381