tgoop.com/llmsecurity/369
Last Update:
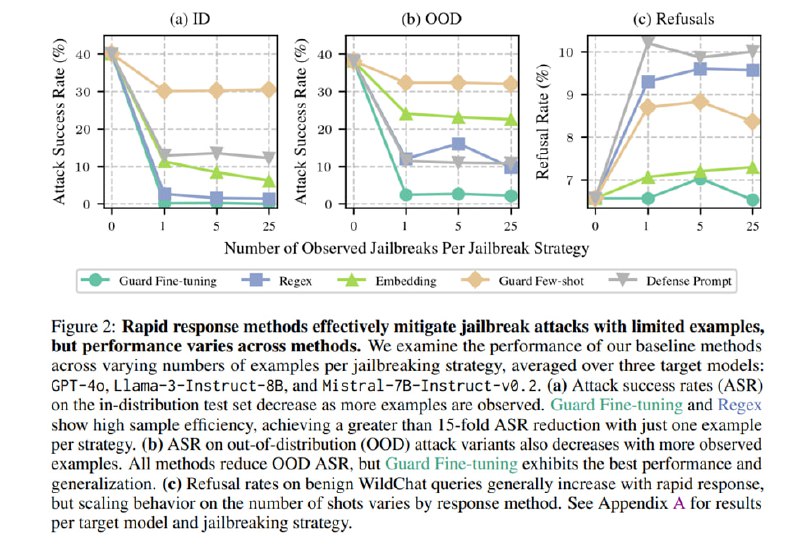
В качестве целевых моделей берут gpt-4o и маленькие Llama-3-8B и Mistral. Для генерации вариаций джейлбрейков используют Llama-3.1-70B-instruct. Дальше исследователи замеряют, сколько нужно примеров, чтобы снизить ASR (процент успеха) для джейбрейка, т.е. насколько у нас возможен rapid response.
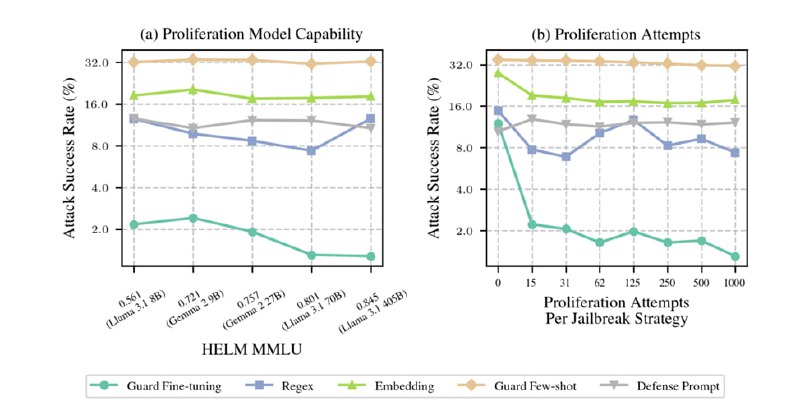
Из графиков видно, что Regex отлично работает на in-distribution и неплохо работает на OOD, но имеет большой FPR, в то время как файн-тюнинг цензора работает лучше всего, особенно с точки зрения адаптации к OOD, хотя манипуляции с осью ординат мешают увидеть сходу, что у всех методов FPR > 6%. Дополнительно исследователи оценивают влияние модели, генерирующей вариации джейлбрейков, и показывают, что чем модель мощнее, тем лучше работает Guard Fine-tuning, в то время как на другие подходы это особого влияния не оказывает.
В целом, работа любопытная, но вопросов к ней очень много. Это и выбор модели для генерации эмбеддингов (неужели на BGE/e5 не хватило карточки?), и то, насколько реально генерация вариаций джейлбрейка с помощью LLM хорошо подходит для файн-тюнинга защит (особенно для итеративных методов), и то, что защита на регексах может быть гораздо эффективнее с точки зрения DR/FPR, если не полениться и написать регексы ручками (извините). Кроме того, есть довольно большие претензии к AdvBench, в котором есть кучи повторяющихся запросов и не очень-то опасных промптов, а также к false refusal rate на уровне 6%, который исследователи (вероятно, не специально) очень неудачно нарисовали на графике (но считать допустимым такой уровень FPR – обычная претензия ко всем академическим работам по детектированию вредоносных объектов). Зато теперь я могу говорить, что даже исследователи из Anthropic подтверждают, что вам нужен цензор и надеяться на alignment пока нельзя