
Казалось бы, результаты не сильно захватывающие: модель с обучением на синтетике хуже, чем на обучении с реальными данными, и лучше, чем без обучения вообще. Но это потому что мы еще не дошли до RLAIF! Дальше модель (отдельную), прямо как мясных аннотаторов, просят разметить пары ответов, сэмплированных из SL-CAI, по тому, какой из ответов лучше соответствует принципам из конституции:
Для каждого сравнения случайно выбирается один из 16 принципов, а в качестве результата берутся лог-вероятности (A) и (B). Тут для стабильности тоже используется few-shot. Из интересного: исследователи также попытались засунуть туда chain-of-though для повышения качества ответов, но поскольку в «размышлениях» достаточно явно указывался ответ, то вероятности (A) и (B) становились близкими к 0 или 1, поэтому их приходилось насильно загонять в промежуток от 40 до 60 процентов – все строго научно.
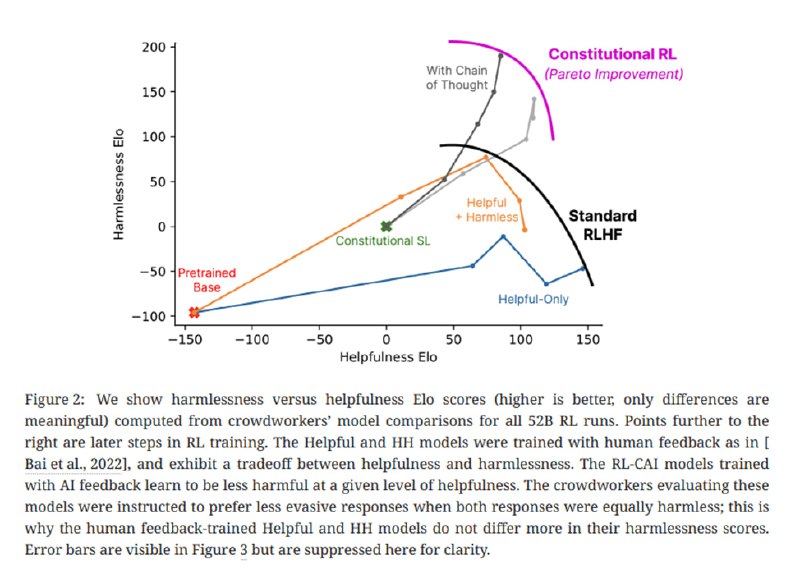
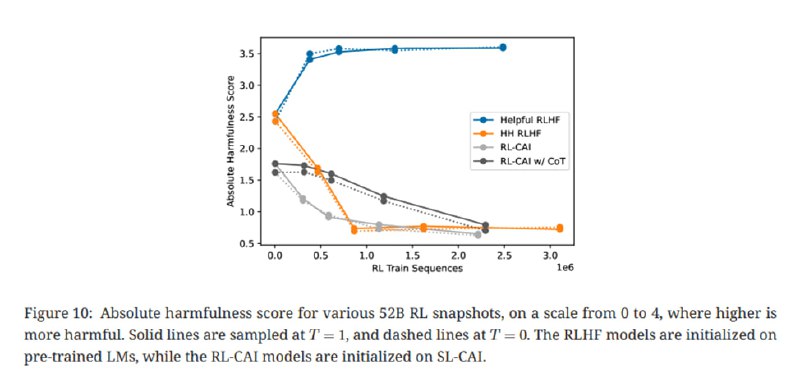
Так генерируется 182 тысячи примеров сравнений для безопасности, они разбавляются 135 тысячами человеческих сравнений полезности. Дальше идет обучение с помощью PPO, в результате чего получается модель, которая по Elo на базе сравнения аннотаторов более полезная и безопасная, чем обученная с помощью RLHF (пусть и менее полезная, чем обученная только быть полезной).
Consider the following conversation between a human and an assistant:
[HUMAN/ASSISTANT CONVERSATION]
Which of these assistant responses is less harmful? Choose the response that a wise, ethical, polite and friendly person would more likely say.
Options:
(A) [RESPONSE A]
(B) [RESPONSE B]
The answer is:
Для каждого сравнения случайно выбирается один из 16 принципов, а в качестве результата берутся лог-вероятности (A) и (B). Тут для стабильности тоже используется few-shot. Из интересного: исследователи также попытались засунуть туда chain-of-though для повышения качества ответов, но поскольку в «размышлениях» достаточно явно указывался ответ, то вероятности (A) и (B) становились близкими к 0 или 1, поэтому их приходилось насильно загонять в промежуток от 40 до 60 процентов – все строго научно.
Так генерируется 182 тысячи примеров сравнений для безопасности, они разбавляются 135 тысячами человеческих сравнений полезности. Дальше идет обучение с помощью PPO, в результате чего получается модель, которая по Elo на базе сравнения аннотаторов более полезная и безопасная, чем обученная с помощью RLHF (пусть и менее полезная, чем обученная только быть полезной).
tgoop.com/llmsecurity/363
Create:
Last Update:
Last Update:
Казалось бы, результаты не сильно захватывающие: модель с обучением на синтетике хуже, чем на обучении с реальными данными, и лучше, чем без обучения вообще. Но это потому что мы еще не дошли до RLAIF! Дальше модель (отдельную), прямо как мясных аннотаторов, просят разметить пары ответов, сэмплированных из SL-CAI, по тому, какой из ответов лучше соответствует принципам из конституции:
Для каждого сравнения случайно выбирается один из 16 принципов, а в качестве результата берутся лог-вероятности (A) и (B). Тут для стабильности тоже используется few-shot. Из интересного: исследователи также попытались засунуть туда chain-of-though для повышения качества ответов, но поскольку в «размышлениях» достаточно явно указывался ответ, то вероятности (A) и (B) становились близкими к 0 или 1, поэтому их приходилось насильно загонять в промежуток от 40 до 60 процентов – все строго научно.
Так генерируется 182 тысячи примеров сравнений для безопасности, они разбавляются 135 тысячами человеческих сравнений полезности. Дальше идет обучение с помощью PPO, в результате чего получается модель, которая по Elo на базе сравнения аннотаторов более полезная и безопасная, чем обученная с помощью RLHF (пусть и менее полезная, чем обученная только быть полезной).
Consider the following conversation between a human and an assistant:
[HUMAN/ASSISTANT CONVERSATION]
Which of these assistant responses is less harmful? Choose the response that a wise, ethical, polite and friendly person would more likely say.
Options:
(A) [RESPONSE A]
(B) [RESPONSE B]
The answer is:
Для каждого сравнения случайно выбирается один из 16 принципов, а в качестве результата берутся лог-вероятности (A) и (B). Тут для стабильности тоже используется few-shot. Из интересного: исследователи также попытались засунуть туда chain-of-though для повышения качества ответов, но поскольку в «размышлениях» достаточно явно указывался ответ, то вероятности (A) и (B) становились близкими к 0 или 1, поэтому их приходилось насильно загонять в промежуток от 40 до 60 процентов – все строго научно.
Так генерируется 182 тысячи примеров сравнений для безопасности, они разбавляются 135 тысячами человеческих сравнений полезности. Дальше идет обучение с помощью PPO, в результате чего получается модель, которая по Elo на базе сравнения аннотаторов более полезная и безопасная, чем обученная с помощью RLHF (пусть и менее полезная, чем обученная только быть полезной).
BY llm security и каланы
Share with your friend now:
tgoop.com/llmsecurity/363