tgoop.com/llmsecurity/357
Last Update:
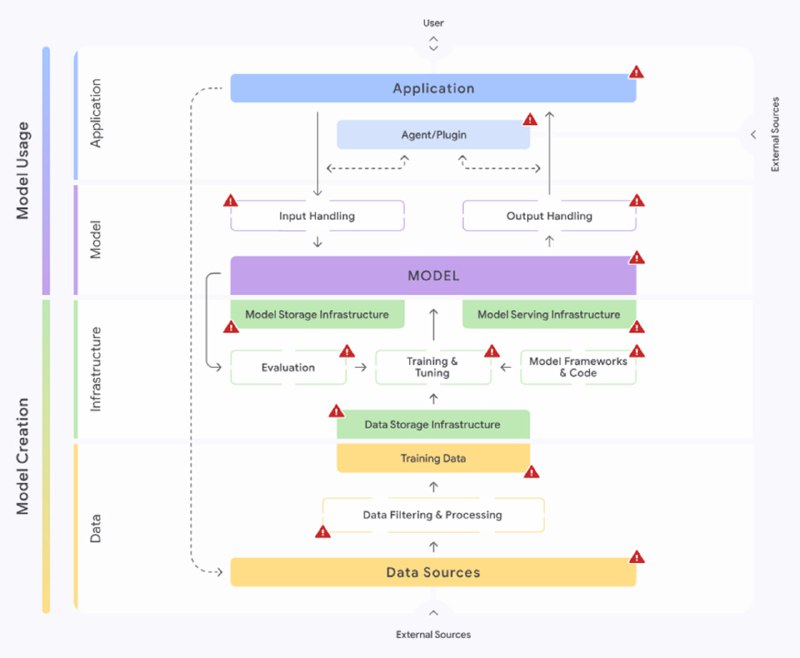
Наконец, всё это отображается на карту, которая показывает процесс разработки ИИ-системы и показывает, на каком этапе может возникнуть тот или иной риск, в чем опасность и как риск митигировать. Карта интерактивная: можно выбирать риски, чтобы визуально все это себе представлять. В дополнение к ней идет AI Development Primer (достаточно подробная статья для не-ML-щиков о том, как делает машинлернинг) и Risk Self Assessment (тест на то, на какие риски стоит обратить внимание в организации).
Этот фреймворк далеко не идеальный: например, мне непонятно, зачем вообще выделять зону «модель», в которую входит «модель», а также некоторая алгоритмическая (не связанная с моделью) составляющая по обработке входов-выводов; компонент агентов-плагинов слегка тенденциозный и в целом скорее про вводы-выводы, т.к. сами плагины обычно имплементируют детерминированную логику, а агенты с ними объединены вообще непонятно за какие заслуги; evaluation и тем более fine-tuning в моем сознании больше про «модель», чем про инфраструктуру и так далее. Тем не менее, есть причины, по которым захотелось про него рассказать. Во-первых, он в равной мере нацелен и службы ИБ, и на разработчиков систем (вроде меня). Во-вторых, он ориентирован на риски, а не уязвимости (строго говоря, хотя на OWASP написано черным по белому a list of the most critical vulnerabilities, model theft это тоже риск, а не уязвимость). В-третьих, он включает дополнительные материалы, которые должны помочь всем акторам (менеджерам, ИБ-шникам и ML-щикам) говорить на одном языке, в отличие от того же ATLAS, и визуальное представление процесса, которое, если общий язык не найден, дает возможность тыкать в это представление пальцем. Последнее, на мой взгляд, очень важно, поэтому если бы я делал свой идеальный фреймворк, который бы потом объяснял разработчикам я бы основывал его скорее на карте SAIF, а не на ATLAS. Возможно, я не знаю про какие-то еще более удачные фреймворки, но если узнаю – обязательно поделюсь