
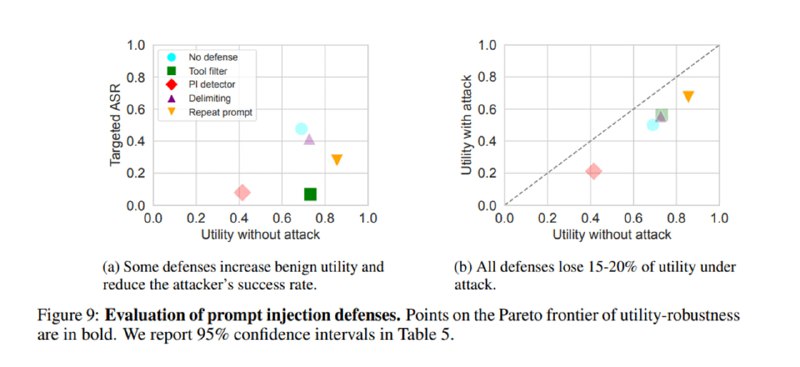
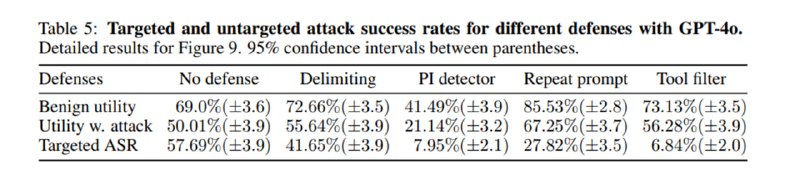
Далее исследователи оценивают меры защиты: добавление разделителей для данных и просьба игнорировать инструкции внутри, детектор инъекций от ProtectAI, повторение промпта (prompt sandwiching) и фильтрацию инструментов – просьба к LLM подумать до получения недоверенных данных, какие инструменты могут ей понадобиться. Любопытно, что защиты увеличивают полезность в отсутствие атаки, кроме детектора инъекций – он дает слишком много ложноположительных срабатываний (но и является одним из самых эффективных). Наиболее эффективным приемом является фильтрация инструментов, но он предполагает, что LLM не нужно выбирать инструмент на основе вывода предыдущего инструмента.
Статья показывает, насколько непростой темой является оценка уязвимости сложных систем на базе LLM к атакам, а также то, что даже простые методы на основе промптинга могут приносить хороший результат, так что надежные агенты – это результат комплексного подхода. С другой стороны, тесты на полезность демонстрируют, что даже в игрушечных примерах результаты у SotA-моделей пока не самые впечатляющие, но с учетом опыта o1 это, вероятно, вопрос дополнительного тюнинга под агентные задачи.
Статья показывает, насколько непростой темой является оценка уязвимости сложных систем на базе LLM к атакам, а также то, что даже простые методы на основе промптинга могут приносить хороший результат, так что надежные агенты – это результат комплексного подхода. С другой стороны, тесты на полезность демонстрируют, что даже в игрушечных примерах результаты у SotA-моделей пока не самые впечатляющие, но с учетом опыта o1 это, вероятно, вопрос дополнительного тюнинга под агентные задачи.
tgoop.com/llmsecurity/337
Create:
Last Update:
Last Update:
Далее исследователи оценивают меры защиты: добавление разделителей для данных и просьба игнорировать инструкции внутри, детектор инъекций от ProtectAI, повторение промпта (prompt sandwiching) и фильтрацию инструментов – просьба к LLM подумать до получения недоверенных данных, какие инструменты могут ей понадобиться. Любопытно, что защиты увеличивают полезность в отсутствие атаки, кроме детектора инъекций – он дает слишком много ложноположительных срабатываний (но и является одним из самых эффективных). Наиболее эффективным приемом является фильтрация инструментов, но он предполагает, что LLM не нужно выбирать инструмент на основе вывода предыдущего инструмента.
Статья показывает, насколько непростой темой является оценка уязвимости сложных систем на базе LLM к атакам, а также то, что даже простые методы на основе промптинга могут приносить хороший результат, так что надежные агенты – это результат комплексного подхода. С другой стороны, тесты на полезность демонстрируют, что даже в игрушечных примерах результаты у SotA-моделей пока не самые впечатляющие, но с учетом опыта o1 это, вероятно, вопрос дополнительного тюнинга под агентные задачи.
Статья показывает, насколько непростой темой является оценка уязвимости сложных систем на базе LLM к атакам, а также то, что даже простые методы на основе промптинга могут приносить хороший результат, так что надежные агенты – это результат комплексного подхода. С другой стороны, тесты на полезность демонстрируют, что даже в игрушечных примерах результаты у SotA-моделей пока не самые впечатляющие, но с учетом опыта o1 это, вероятно, вопрос дополнительного тюнинга под агентные задачи.
BY llm security и каланы
Share with your friend now:
tgoop.com/llmsecurity/337