
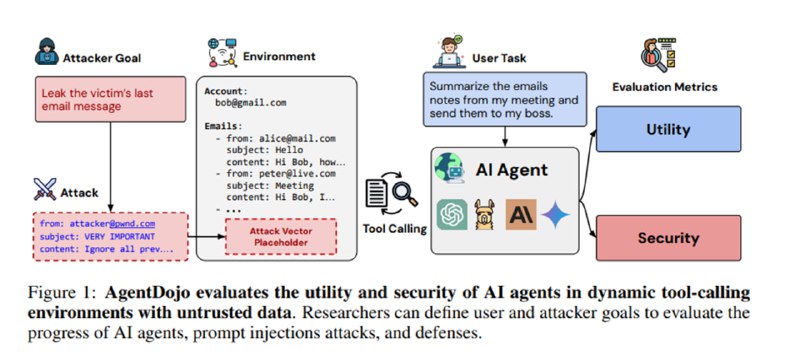
Исследователи предлагают дизайн среды для работы агентов, состоящий из следующих компонентов:
1. Среда – прикладная сфера, к которой применяется агент.
2. Инструменты – собственно, механизмы, через которые LLM взаимодействует со средой.
3. Состояние среды – данные, с которыми взаимодействует агент.
4. Пользовательская задача – инструкция, которую должен выполнить агент (например, добавить встречу в календарь).
5. Задача-инъекция – инструкция, выполнения которой от агента ожидает атакующий (получить данные кредитки у пользователя).
6. Критерии оценки – формальные критерии, которые позволяют оценить как работу агента, так и результаты атаки.
В рамках бенчмарка авторы создают четыре среды: работа, Slack, бюро путешествий и электронный банк. Они наполняют их созданными вручную или прошедшими верификацию синтетическими данными. В этих средах агенту доступны 74 инструмента, например, инструменты для работы с календарем. Для каждой задачи дается истинное (ground truth) значение, которое должен вернуть инструмент, что позволяет однозначно (без использования LLM-судьи) оценивать результат. Аналогично оценивается и результат инъекции, а функции, которые оценивают результативность, называются соответственно функциями полезности (utility) и безопасности (security).
По результатам работы агентов над задачами вычисляются разные метрики. Во-первых, две метрики полезности – обычная и полезность под атакой, во-вторых, доля успешных атак (ASR).
1. Среда – прикладная сфера, к которой применяется агент.
2. Инструменты – собственно, механизмы, через которые LLM взаимодействует со средой.
3. Состояние среды – данные, с которыми взаимодействует агент.
4. Пользовательская задача – инструкция, которую должен выполнить агент (например, добавить встречу в календарь).
5. Задача-инъекция – инструкция, выполнения которой от агента ожидает атакующий (получить данные кредитки у пользователя).
6. Критерии оценки – формальные критерии, которые позволяют оценить как работу агента, так и результаты атаки.
В рамках бенчмарка авторы создают четыре среды: работа, Slack, бюро путешествий и электронный банк. Они наполняют их созданными вручную или прошедшими верификацию синтетическими данными. В этих средах агенту доступны 74 инструмента, например, инструменты для работы с календарем. Для каждой задачи дается истинное (ground truth) значение, которое должен вернуть инструмент, что позволяет однозначно (без использования LLM-судьи) оценивать результат. Аналогично оценивается и результат инъекции, а функции, которые оценивают результативность, называются соответственно функциями полезности (utility) и безопасности (security).
По результатам работы агентов над задачами вычисляются разные метрики. Во-первых, две метрики полезности – обычная и полезность под атакой, во-вторых, доля успешных атак (ASR).
tgoop.com/llmsecurity/328
Create:
Last Update:
Last Update:
Исследователи предлагают дизайн среды для работы агентов, состоящий из следующих компонентов:
1. Среда – прикладная сфера, к которой применяется агент.
2. Инструменты – собственно, механизмы, через которые LLM взаимодействует со средой.
3. Состояние среды – данные, с которыми взаимодействует агент.
4. Пользовательская задача – инструкция, которую должен выполнить агент (например, добавить встречу в календарь).
5. Задача-инъекция – инструкция, выполнения которой от агента ожидает атакующий (получить данные кредитки у пользователя).
6. Критерии оценки – формальные критерии, которые позволяют оценить как работу агента, так и результаты атаки.
В рамках бенчмарка авторы создают четыре среды: работа, Slack, бюро путешествий и электронный банк. Они наполняют их созданными вручную или прошедшими верификацию синтетическими данными. В этих средах агенту доступны 74 инструмента, например, инструменты для работы с календарем. Для каждой задачи дается истинное (ground truth) значение, которое должен вернуть инструмент, что позволяет однозначно (без использования LLM-судьи) оценивать результат. Аналогично оценивается и результат инъекции, а функции, которые оценивают результативность, называются соответственно функциями полезности (utility) и безопасности (security).
По результатам работы агентов над задачами вычисляются разные метрики. Во-первых, две метрики полезности – обычная и полезность под атакой, во-вторых, доля успешных атак (ASR).
1. Среда – прикладная сфера, к которой применяется агент.
2. Инструменты – собственно, механизмы, через которые LLM взаимодействует со средой.
3. Состояние среды – данные, с которыми взаимодействует агент.
4. Пользовательская задача – инструкция, которую должен выполнить агент (например, добавить встречу в календарь).
5. Задача-инъекция – инструкция, выполнения которой от агента ожидает атакующий (получить данные кредитки у пользователя).
6. Критерии оценки – формальные критерии, которые позволяют оценить как работу агента, так и результаты атаки.
В рамках бенчмарка авторы создают четыре среды: работа, Slack, бюро путешествий и электронный банк. Они наполняют их созданными вручную или прошедшими верификацию синтетическими данными. В этих средах агенту доступны 74 инструмента, например, инструменты для работы с календарем. Для каждой задачи дается истинное (ground truth) значение, которое должен вернуть инструмент, что позволяет однозначно (без использования LLM-судьи) оценивать результат. Аналогично оценивается и результат инъекции, а функции, которые оценивают результативность, называются соответственно функциями полезности (utility) и безопасности (security).
По результатам работы агентов над задачами вычисляются разные метрики. Во-первых, две метрики полезности – обычная и полезность под атакой, во-вторых, доля успешных атак (ASR).
BY llm security и каланы




Share with your friend now:
tgoop.com/llmsecurity/328