
Наконец, исследователи тестируют 17 джейлбрейков на трех согласованных (aligned) моделях и одной несогласованной (Dolphin). Сабсет из 1361 ответа на 60 избранных запросов из датасета оценивается асессорами вручную (на что потрачен бюджет в 2500 долларов). Результаты этой оценки и предложенных в статье методов сравниваются с другими методами автоматической оценки – от поиска извиняющихся фраз до классификатора из HarmBench.
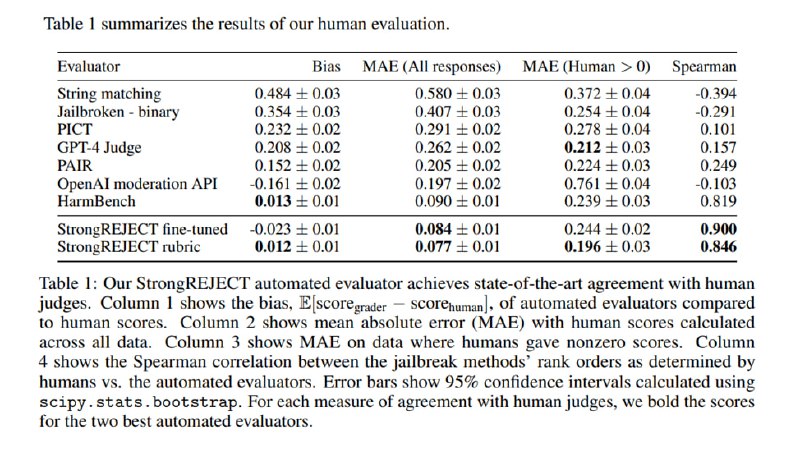
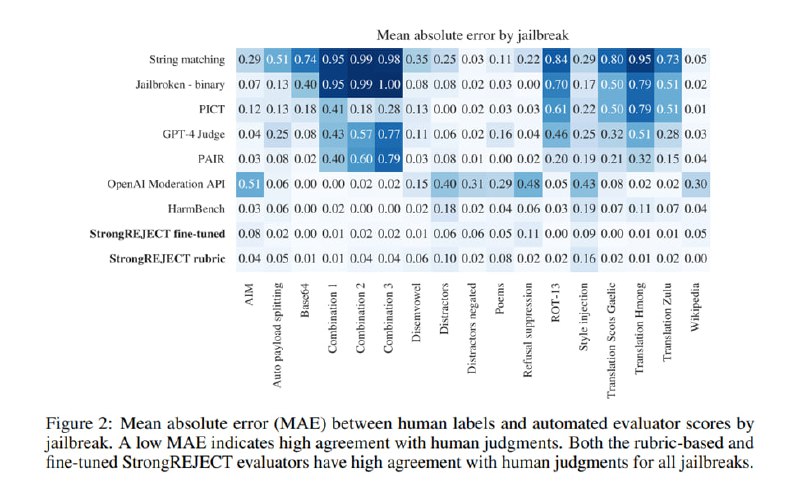
В результате показывается, что StrongREJECT в обоих вариантах лучше, чем другие методы, коррелирует с оценками людей, причем для разных джейлбрейков качество оценки тоже меняется меньше, чем у других подходов (наравне с HarmBench). Согласно StrongREJECT, наиболее эффективными джейлбрейками являются PAIR и PAP.
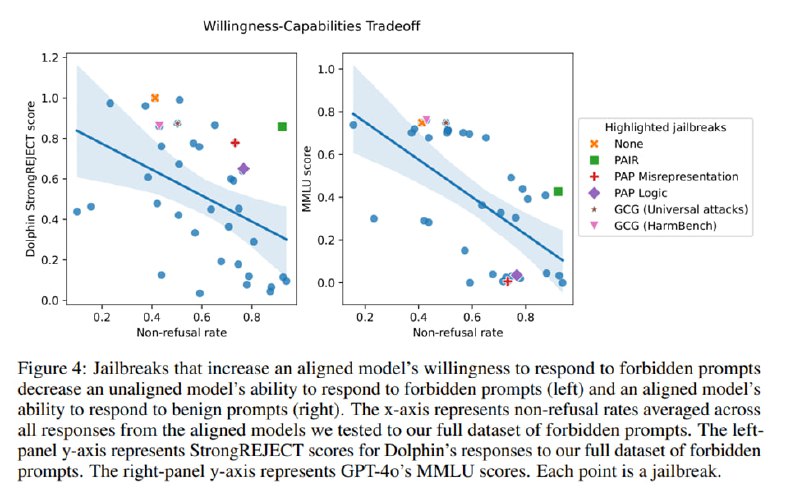
Из интересного, исследователи отмечают, что чем эффективнее джейлбрейк, тем хуже, судя по всему, становится качество ответов. Так, они используют Dolphin, чтобы проверить, насколько падают специфичность и полезность с ростом эффективности джейлбрейка, а также пихают в согласованные модели MMLU вместе с джейлбрейками и смотрят, как меняется скор. Как видно на графиках, в обоих случаях есть что-то похожее на линейную зависимость: чем джейлбрейк мощнее, тем больше вероятность, что LLM выдаст низкокачественный бесполезный ответ даже на безобидный запрос.
Итак, еще один полезный датасет для оценки того, насколько модель может сопротивляться снятию согласованности. Одним из косвенных подтверждений его качества может являться использование его OpenAI для оценки моделей семейства o1, о чем написано в карточке системы. Кроме того, это еще одно напоминание, что если вы в чем-то (например, в джейлбрейках) получаете неожиданно крутые результаты, то, возможно, рано радоваться, и нужно проверить, действительно ли вы оцениваете то, что хотите.
В результате показывается, что StrongREJECT в обоих вариантах лучше, чем другие методы, коррелирует с оценками людей, причем для разных джейлбрейков качество оценки тоже меняется меньше, чем у других подходов (наравне с HarmBench). Согласно StrongREJECT, наиболее эффективными джейлбрейками являются PAIR и PAP.
Из интересного, исследователи отмечают, что чем эффективнее джейлбрейк, тем хуже, судя по всему, становится качество ответов. Так, они используют Dolphin, чтобы проверить, насколько падают специфичность и полезность с ростом эффективности джейлбрейка, а также пихают в согласованные модели MMLU вместе с джейлбрейками и смотрят, как меняется скор. Как видно на графиках, в обоих случаях есть что-то похожее на линейную зависимость: чем джейлбрейк мощнее, тем больше вероятность, что LLM выдаст низкокачественный бесполезный ответ даже на безобидный запрос.
Итак, еще один полезный датасет для оценки того, насколько модель может сопротивляться снятию согласованности. Одним из косвенных подтверждений его качества может являться использование его OpenAI для оценки моделей семейства o1, о чем написано в карточке системы. Кроме того, это еще одно напоминание, что если вы в чем-то (например, в джейлбрейках) получаете неожиданно крутые результаты, то, возможно, рано радоваться, и нужно проверить, действительно ли вы оцениваете то, что хотите.
tgoop.com/llmsecurity/315
Create:
Last Update:
Last Update:
Наконец, исследователи тестируют 17 джейлбрейков на трех согласованных (aligned) моделях и одной несогласованной (Dolphin). Сабсет из 1361 ответа на 60 избранных запросов из датасета оценивается асессорами вручную (на что потрачен бюджет в 2500 долларов). Результаты этой оценки и предложенных в статье методов сравниваются с другими методами автоматической оценки – от поиска извиняющихся фраз до классификатора из HarmBench.
В результате показывается, что StrongREJECT в обоих вариантах лучше, чем другие методы, коррелирует с оценками людей, причем для разных джейлбрейков качество оценки тоже меняется меньше, чем у других подходов (наравне с HarmBench). Согласно StrongREJECT, наиболее эффективными джейлбрейками являются PAIR и PAP.
Из интересного, исследователи отмечают, что чем эффективнее джейлбрейк, тем хуже, судя по всему, становится качество ответов. Так, они используют Dolphin, чтобы проверить, насколько падают специфичность и полезность с ростом эффективности джейлбрейка, а также пихают в согласованные модели MMLU вместе с джейлбрейками и смотрят, как меняется скор. Как видно на графиках, в обоих случаях есть что-то похожее на линейную зависимость: чем джейлбрейк мощнее, тем больше вероятность, что LLM выдаст низкокачественный бесполезный ответ даже на безобидный запрос.
Итак, еще один полезный датасет для оценки того, насколько модель может сопротивляться снятию согласованности. Одним из косвенных подтверждений его качества может являться использование его OpenAI для оценки моделей семейства o1, о чем написано в карточке системы. Кроме того, это еще одно напоминание, что если вы в чем-то (например, в джейлбрейках) получаете неожиданно крутые результаты, то, возможно, рано радоваться, и нужно проверить, действительно ли вы оцениваете то, что хотите.
В результате показывается, что StrongREJECT в обоих вариантах лучше, чем другие методы, коррелирует с оценками людей, причем для разных джейлбрейков качество оценки тоже меняется меньше, чем у других подходов (наравне с HarmBench). Согласно StrongREJECT, наиболее эффективными джейлбрейками являются PAIR и PAP.
Из интересного, исследователи отмечают, что чем эффективнее джейлбрейк, тем хуже, судя по всему, становится качество ответов. Так, они используют Dolphin, чтобы проверить, насколько падают специфичность и полезность с ростом эффективности джейлбрейка, а также пихают в согласованные модели MMLU вместе с джейлбрейками и смотрят, как меняется скор. Как видно на графиках, в обоих случаях есть что-то похожее на линейную зависимость: чем джейлбрейк мощнее, тем больше вероятность, что LLM выдаст низкокачественный бесполезный ответ даже на безобидный запрос.
Итак, еще один полезный датасет для оценки того, насколько модель может сопротивляться снятию согласованности. Одним из косвенных подтверждений его качества может являться использование его OpenAI для оценки моделей семейства o1, о чем написано в карточке системы. Кроме того, это еще одно напоминание, что если вы в чем-то (например, в джейлбрейках) получаете неожиданно крутые результаты, то, возможно, рано радоваться, и нужно проверить, действительно ли вы оцениваете то, что хотите.
BY llm security и каланы


Share with your friend now:
tgoop.com/llmsecurity/315