
tgoop.com/llmsecurity/29
Last Update:
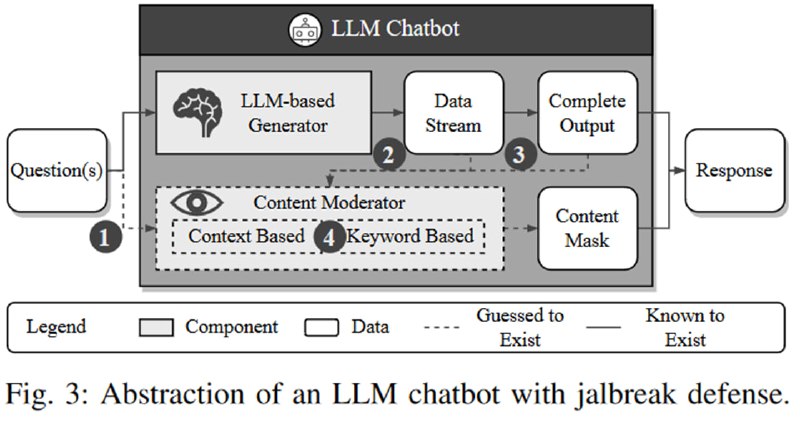
Исследователи прилагают довольно много усилий, делают тысячи запросов с просьбой сгенерировать у каждого из сервисов то иное количество токенов и делают захватывающий вывод, что время генерации зависит от длины сгенерированного текста. Затем они подмечают, также весьма глубоко, что если происходит фильтрация входа, то генерация должна быть мгновенной, потому что ее нет, а вот если работает пост-фильтрация, то генерация займет больше времени.
Чуть менее тривиальным является замечание, что пост-фильтрация может быть на основе машинлернинга (другой LLM, например), а может быть на основе ключевых слов, причем и та, и другая может быть потоковая (dynamic), чтобы после нарушения сразу приостанавливать генерацию и освобождать ресурсы. Во втором случае наличие такой фильтрации можно заметить, если попросить LLM сгенерировать запретное слово на n-ной позиции.
Исследователи проводят соответствующие тесты и выявляют, что Bard и Bing Chat имеют два типа пост-фильтрации (потоковые) и не имеют пре-фильтрации. В случае Bing Chat, которые теперь Microsoft Copilot, это не соответствует моим наблюдениям (просто посмотрите на трафик между фронтом и бэкендом и поймете, о чем я).
BY llm security и каланы
Share with your friend now:
tgoop.com/llmsecurity/29