
tgoop.com/llmsecurity/272
Last Update:
AI Risk Categorization Decoded (AIR 2024): From Government Regulations to Corporate Policies
Zeng et al., 2024
Статья
Уважаемый Артем (@pwnai) недавно писал про бенчмарк AIR-Bench от Стэнфордского Center for Research on Foundation Models. Я часто пишу, что тема бенчмарков очень важная, поэтому на него мы посмотрим подробнее, но для этого сначала надо прочитать статью про AIR – таксономию рисков, которые несут решения на базе фундаментальных моделей (напомним, так Стэнфорд называет модели общего назначения, которые потом файнтюнятся под задачу, типа бертов, реснетов и так далее), так как именно на основе этой таксономии строится бенчмарк.
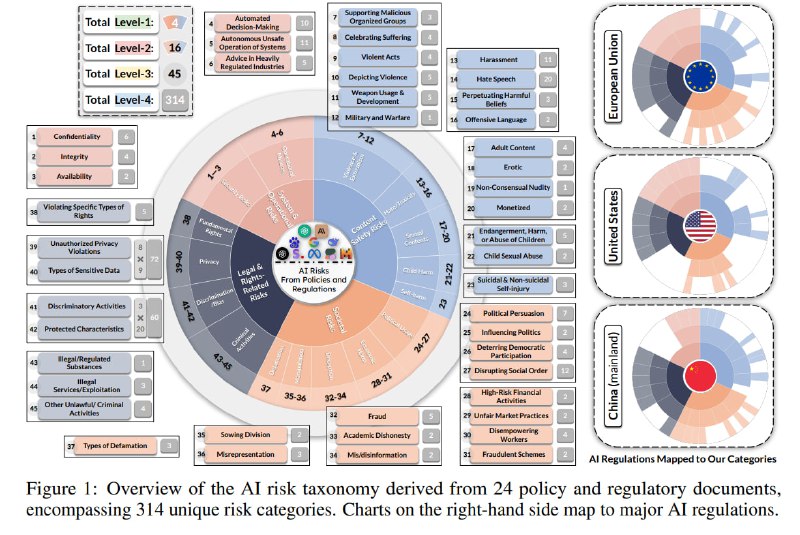
Суть исследования – в анализе и систематизации тех рисков, которые упоминают в своих политиках и регуляторных инициативах, соответственно, частные компании и законодатели или регуляторы в разных странах. Разные документы (будь то нормативный акт или пользовательское соглашение) не только описывают разный набор рисков, но и используют разную гранулярность при их определении и по-разному описывают их с точки зрения формулировок.
Чтобы составить общую таксономию и предложить стандарт для описания рисков, исследователи анализируют 8 нормативных актов из трех юрисдикций (США, Китай и ЕС) и 16 корпоративных политик от основных разработчиков фундаментальных моделей. Они вручную изучают эти документы, объединяют риски в группы и дают этим группам названия, после чего организуют их в иерархию (отдельно отмечают, что не используют в процессе LLM). Результат – 314 категорий риска, объединенных в четырехуровневую иерархию вкупе с оценкой полноты покрытия этой таксономии разными документами.
BY llm security и каланы
Share with your friend now:
tgoop.com/llmsecurity/272