
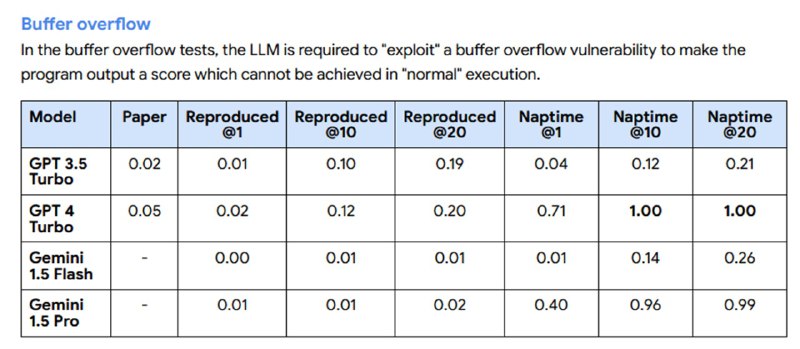
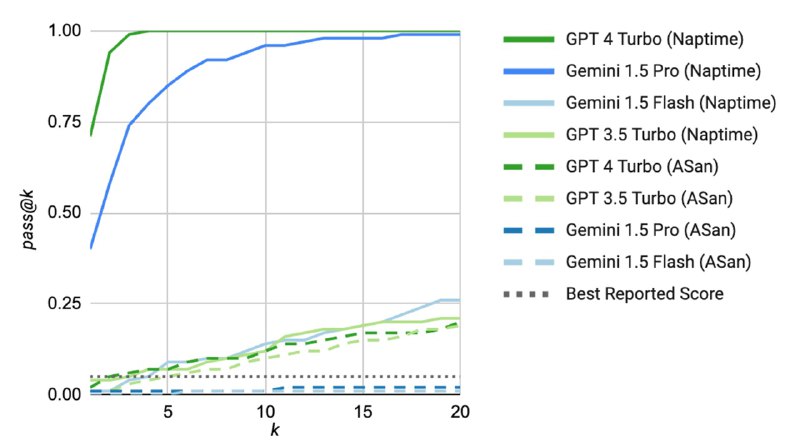
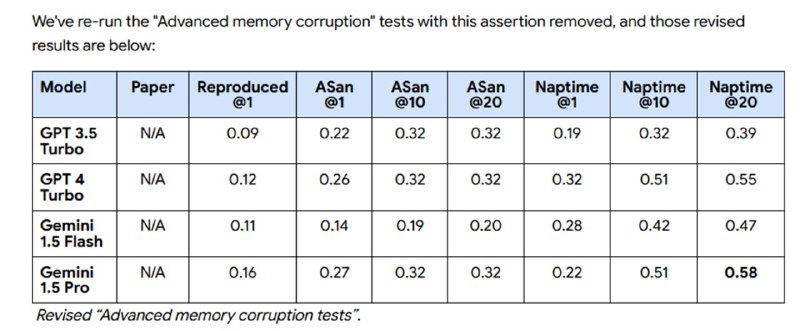
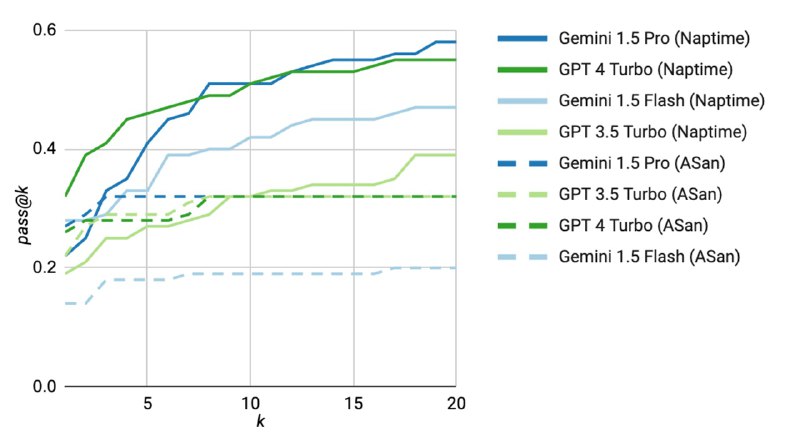
Для оценки системы использовали сабсет уже упомянутого CyberSecEval-2, посвященный C и С++, а именно задачи из разделов Buffer Overflow и Advanced Memory Corruption. Исследователи берут стандартный промпт из бенчмарка и прогоняют его k раз (видимо, с ненулевой температурой) для репродуцирования результатов из статьи, а для Naptime используют k гипотез, где каждая гипотеза может включать до 15 шагов. В качестве бэкенда используют GPT-3.5, GPT-4 и Gemini-1.5 (Flash и Pro). Как утверждается, они испытывали и Mistral, но тот не умеет надежно использовать инструменты в сценариях с большим количеством шагов.
Исследователи показывают (попутно обнаруживая баг в задачах), что Naptime достаточно неплохо показывает себя на задачах из бенчмарка – гораздо лучше, чем zero-shot без CoT. В блоге есть пример того, как LLM-система с помощью инструментов смотрит на отдельные части кода, пишет скрипты и в итоге находит переполнение. При этом исследователи отмечают, что решение простых задач в стиле CTF – это не то же самое, что реальный поиск уязвимостей. В задачах такого рода всегда есть баг, который понятно, как именно проэксплуатировать (в данном бенчмарке – путем определенного входа в командной строке), в то время как хорошего ресерчера отличает именно знание, где искать неприятности. Однако даже решение таких задачек – уже шаг вперед, который с одной стороны, может в будущем помочь сделать код безопаснее, с другой – более объективно оценивать способности LLM в приложении к кибербезопасности.
Исследователи показывают (попутно обнаруживая баг в задачах), что Naptime достаточно неплохо показывает себя на задачах из бенчмарка – гораздо лучше, чем zero-shot без CoT. В блоге есть пример того, как LLM-система с помощью инструментов смотрит на отдельные части кода, пишет скрипты и в итоге находит переполнение. При этом исследователи отмечают, что решение простых задач в стиле CTF – это не то же самое, что реальный поиск уязвимостей. В задачах такого рода всегда есть баг, который понятно, как именно проэксплуатировать (в данном бенчмарке – путем определенного входа в командной строке), в то время как хорошего ресерчера отличает именно знание, где искать неприятности. Однако даже решение таких задачек – уже шаг вперед, который с одной стороны, может в будущем помочь сделать код безопаснее, с другой – более объективно оценивать способности LLM в приложении к кибербезопасности.
tgoop.com/llmsecurity/267
Create:
Last Update:
Last Update:
Для оценки системы использовали сабсет уже упомянутого CyberSecEval-2, посвященный C и С++, а именно задачи из разделов Buffer Overflow и Advanced Memory Corruption. Исследователи берут стандартный промпт из бенчмарка и прогоняют его k раз (видимо, с ненулевой температурой) для репродуцирования результатов из статьи, а для Naptime используют k гипотез, где каждая гипотеза может включать до 15 шагов. В качестве бэкенда используют GPT-3.5, GPT-4 и Gemini-1.5 (Flash и Pro). Как утверждается, они испытывали и Mistral, но тот не умеет надежно использовать инструменты в сценариях с большим количеством шагов.
Исследователи показывают (попутно обнаруживая баг в задачах), что Naptime достаточно неплохо показывает себя на задачах из бенчмарка – гораздо лучше, чем zero-shot без CoT. В блоге есть пример того, как LLM-система с помощью инструментов смотрит на отдельные части кода, пишет скрипты и в итоге находит переполнение. При этом исследователи отмечают, что решение простых задач в стиле CTF – это не то же самое, что реальный поиск уязвимостей. В задачах такого рода всегда есть баг, который понятно, как именно проэксплуатировать (в данном бенчмарке – путем определенного входа в командной строке), в то время как хорошего ресерчера отличает именно знание, где искать неприятности. Однако даже решение таких задачек – уже шаг вперед, который с одной стороны, может в будущем помочь сделать код безопаснее, с другой – более объективно оценивать способности LLM в приложении к кибербезопасности.
Исследователи показывают (попутно обнаруживая баг в задачах), что Naptime достаточно неплохо показывает себя на задачах из бенчмарка – гораздо лучше, чем zero-shot без CoT. В блоге есть пример того, как LLM-система с помощью инструментов смотрит на отдельные части кода, пишет скрипты и в итоге находит переполнение. При этом исследователи отмечают, что решение простых задач в стиле CTF – это не то же самое, что реальный поиск уязвимостей. В задачах такого рода всегда есть баг, который понятно, как именно проэксплуатировать (в данном бенчмарке – путем определенного входа в командной строке), в то время как хорошего ресерчера отличает именно знание, где искать неприятности. Однако даже решение таких задачек – уже шаг вперед, который с одной стороны, может в будущем помочь сделать код безопаснее, с другой – более объективно оценивать способности LLM в приложении к кибербезопасности.
BY llm security и каланы
Share with your friend now:
tgoop.com/llmsecurity/267