
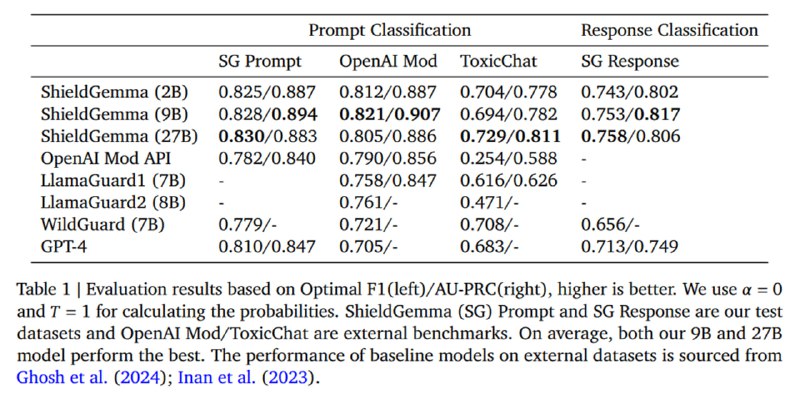
Результаты оценивают на тестовой части датасета, а также на популярных датасетах OpenAI Moderation и ToxicChat, сравнивая с другими моделями (OpenAI Moderation API, LlamaGuard двух версий, WildGuard и GPT-4) на бинарной задаче предсказания. Разумеется, ShieldGemma всех побеждает, но что любопытно – разница между моделями разного размера очень незначительная – разницы после SFT между моделями на 2 и 27 миллиарда параметров почти нет, видимо, 2 миллиардов параметров достаточно, чтобы выучить из датасета все, что можно. При этом в целом метрики не сильно впечатляющие, но сами цифры, без возможности посмотреть неопубликованный датасет значат мало.
Исследователи также оценивают свои модели и на задаче гранулярного предсказания типа вредоносного контента (нужно заметить, что, следуя примеру из LlamaGuard, они делают это в формате one-vs-all, т.е. для каждой категории используют отдельный прогон с отдельным промптом). Специализированная модель обгоняет zero-shot GPT-4 (вот бы они ее или хотя бы gpt-3.5-turbo на этом датасете пофайнтюнили), причем разница между моделями разного размера снова весьма невелика.
Исследователи также оценивают свои модели и на задаче гранулярного предсказания типа вредоносного контента (нужно заметить, что, следуя примеру из LlamaGuard, они делают это в формате one-vs-all, т.е. для каждой категории используют отдельный прогон с отдельным промптом). Специализированная модель обгоняет zero-shot GPT-4 (вот бы они ее или хотя бы gpt-3.5-turbo на этом датасете пофайнтюнили), причем разница между моделями разного размера снова весьма невелика.
tgoop.com/llmsecurity/259
Create:
Last Update:
Last Update:
Результаты оценивают на тестовой части датасета, а также на популярных датасетах OpenAI Moderation и ToxicChat, сравнивая с другими моделями (OpenAI Moderation API, LlamaGuard двух версий, WildGuard и GPT-4) на бинарной задаче предсказания. Разумеется, ShieldGemma всех побеждает, но что любопытно – разница между моделями разного размера очень незначительная – разницы после SFT между моделями на 2 и 27 миллиарда параметров почти нет, видимо, 2 миллиардов параметров достаточно, чтобы выучить из датасета все, что можно. При этом в целом метрики не сильно впечатляющие, но сами цифры, без возможности посмотреть неопубликованный датасет значат мало.
Исследователи также оценивают свои модели и на задаче гранулярного предсказания типа вредоносного контента (нужно заметить, что, следуя примеру из LlamaGuard, они делают это в формате one-vs-all, т.е. для каждой категории используют отдельный прогон с отдельным промптом). Специализированная модель обгоняет zero-shot GPT-4 (вот бы они ее или хотя бы gpt-3.5-turbo на этом датасете пофайнтюнили), причем разница между моделями разного размера снова весьма невелика.
Исследователи также оценивают свои модели и на задаче гранулярного предсказания типа вредоносного контента (нужно заметить, что, следуя примеру из LlamaGuard, они делают это в формате one-vs-all, т.е. для каждой категории используют отдельный прогон с отдельным промптом). Специализированная модель обгоняет zero-shot GPT-4 (вот бы они ее или хотя бы gpt-3.5-turbo на этом датасете пофайнтюнили), причем разница между моделями разного размера снова весьма невелика.
BY llm security и каланы

Share with your friend now:
tgoop.com/llmsecurity/259