
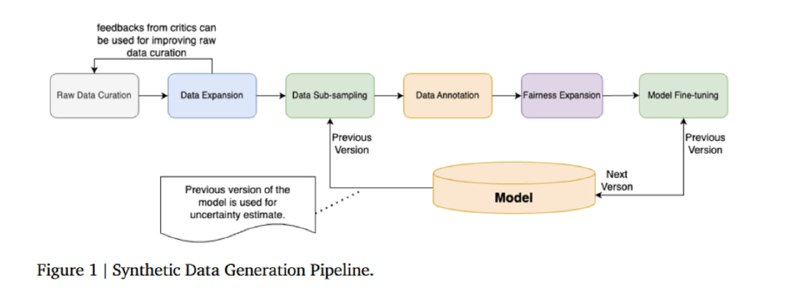
Для обучения модели используется синтетический датасет размером в 50 тысяч запросов и 50 тысяч пар (запрос, ответ), который генерируют с помощью Gemini. К этому добавляется по 5к запросов и пар (запрос, ответ), сгенерированных на основе примеров с просьбой к LLM-генератору написать запрос, который или увеличивает разнообразие датасета, или сложность задачи. Поверх в датасет засыпают кусок из датасета hh-rlhf от Antropic для разнообразия. Затем исследователи, видимо, понимают, что качество всего этого получилось не лучшим, и решают разметить это вручную, пропустив через трех аннотаторов. Но, видимо, оценить все не хватает то ли денег, то ли времени, то ли хватает совести, и они делают из 15 тысяч примеров (половина – запросы, половина – пары с запросом и ответом), используя нехитрый алгоритм с кластеризацией бертовых эмбеддингов для максимального разнообразия. Данные делятся на обучающие и тестовые в пропорции 10500 к 4500. Затем к ним применяется еще один шаг увеличения разнообразия в виде добавления примеров, где заменены на дополнительные гендерные, этнические, религиозные и прочие атрибуты.
На всем этом богатстве файнтюнят (SFT) модели из семейства Gemma-2 в трех размерах. Для каждого из видов запрещенного контента в запрос помещают соответствующий отрывок из политики. Интересно, что в промпте зачем-то используется chain-of-thought промптинг (And then walk through step by step to be sure we answer correctly), но, видимо, для простоты и быстроты использования вердикт модель выдает до рассуждений.
На всем этом богатстве файнтюнят (SFT) модели из семейства Gemma-2 в трех размерах. Для каждого из видов запрещенного контента в запрос помещают соответствующий отрывок из политики. Интересно, что в промпте зачем-то используется chain-of-thought промптинг (And then walk through step by step to be sure we answer correctly), но, видимо, для простоты и быстроты использования вердикт модель выдает до рассуждений.
tgoop.com/llmsecurity/256
Create:
Last Update:
Last Update:
Для обучения модели используется синтетический датасет размером в 50 тысяч запросов и 50 тысяч пар (запрос, ответ), который генерируют с помощью Gemini. К этому добавляется по 5к запросов и пар (запрос, ответ), сгенерированных на основе примеров с просьбой к LLM-генератору написать запрос, который или увеличивает разнообразие датасета, или сложность задачи. Поверх в датасет засыпают кусок из датасета hh-rlhf от Antropic для разнообразия. Затем исследователи, видимо, понимают, что качество всего этого получилось не лучшим, и решают разметить это вручную, пропустив через трех аннотаторов. Но, видимо, оценить все не хватает то ли денег, то ли времени, то ли хватает совести, и они делают из 15 тысяч примеров (половина – запросы, половина – пары с запросом и ответом), используя нехитрый алгоритм с кластеризацией бертовых эмбеддингов для максимального разнообразия. Данные делятся на обучающие и тестовые в пропорции 10500 к 4500. Затем к ним применяется еще один шаг увеличения разнообразия в виде добавления примеров, где заменены на дополнительные гендерные, этнические, религиозные и прочие атрибуты.
На всем этом богатстве файнтюнят (SFT) модели из семейства Gemma-2 в трех размерах. Для каждого из видов запрещенного контента в запрос помещают соответствующий отрывок из политики. Интересно, что в промпте зачем-то используется chain-of-thought промптинг (And then walk through step by step to be sure we answer correctly), но, видимо, для простоты и быстроты использования вердикт модель выдает до рассуждений.
На всем этом богатстве файнтюнят (SFT) модели из семейства Gemma-2 в трех размерах. Для каждого из видов запрещенного контента в запрос помещают соответствующий отрывок из политики. Интересно, что в промпте зачем-то используется chain-of-thought промптинг (And then walk through step by step to be sure we answer correctly), но, видимо, для простоты и быстроты использования вердикт модель выдает до рассуждений.
BY llm security и каланы

Share with your friend now:
tgoop.com/llmsecurity/256