
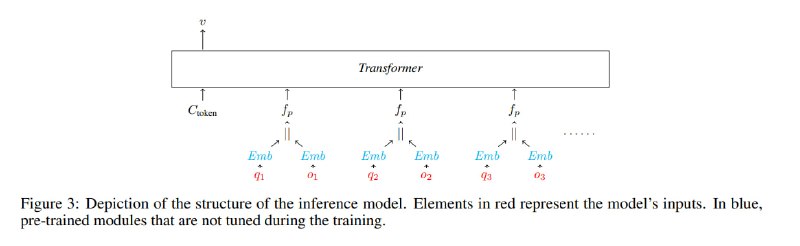
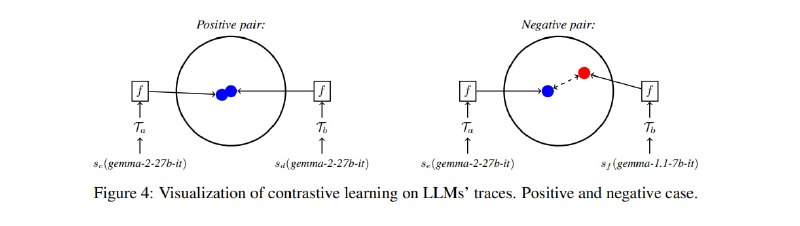
Дальше исследователи дают себе волю и начинают учить модели, да так, что обои от стен отклеиваются. Запрос и ответ по отдельности прогоняются через некоторую предобученную модель для получения эмбеддингов (multilingual-e5-large-instruct). Затем эти эмбеддинги конкатенируются. Из сконкатенированных пар эмбеддингов для разных запросов и ответов собираются приложения, которые вместе со служебным токеном подаются в легковесную сеточку из нескольких слоев трансформера (без позиционных эмбеддингов, т.к. порядок запросов не важен). Кроме того, исследователи обучают эту же сеть как сиамскую с контрастивной функцией потерь для того, чтобы получать отпечатки ответов сервиса, независимые от известных на данный момент архитектур, и потенциально расширять эту модель на работу с не вошедшими в обучающий набор сетями.
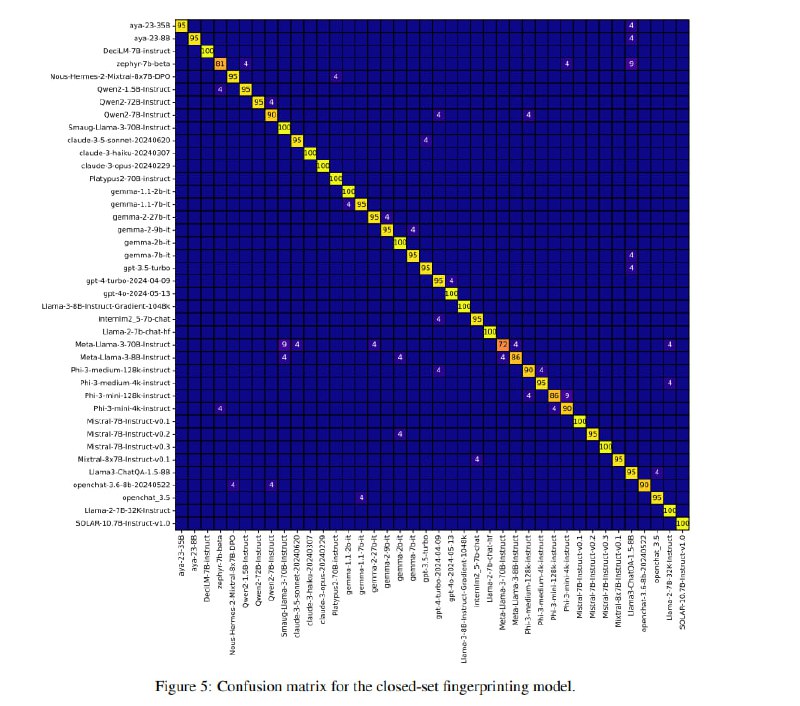
Все это обучается на ответах 40 LLM (из топов HuggingFace Hub по скачиваниям), использованных в разных контекстах: с разными системными промптами, параметрами сэмплирования и даже с использованием RAG и CoT – в итоге в 1000 различных комбинациях. В итоге supervised-модель дает точность в 95% (неплохо для 40 классов). Наибольшие трудности модели доставляют файнтюны Llama, что в целом ожидаемо. Контрастивная модель выдает точность в 90% на LLM, которые она видела, и 81% на неизвестных (посчитано с помощью leave-one-out-метода).
Все это обучается на ответах 40 LLM (из топов HuggingFace Hub по скачиваниям), использованных в разных контекстах: с разными системными промптами, параметрами сэмплирования и даже с использованием RAG и CoT – в итоге в 1000 различных комбинациях. В итоге supervised-модель дает точность в 95% (неплохо для 40 классов). Наибольшие трудности модели доставляют файнтюны Llama, что в целом ожидаемо. Контрастивная модель выдает точность в 90% на LLM, которые она видела, и 81% на неизвестных (посчитано с помощью leave-one-out-метода).
tgoop.com/llmsecurity/243
Create:
Last Update:
Last Update:
Дальше исследователи дают себе волю и начинают учить модели, да так, что обои от стен отклеиваются. Запрос и ответ по отдельности прогоняются через некоторую предобученную модель для получения эмбеддингов (multilingual-e5-large-instruct). Затем эти эмбеддинги конкатенируются. Из сконкатенированных пар эмбеддингов для разных запросов и ответов собираются приложения, которые вместе со служебным токеном подаются в легковесную сеточку из нескольких слоев трансформера (без позиционных эмбеддингов, т.к. порядок запросов не важен). Кроме того, исследователи обучают эту же сеть как сиамскую с контрастивной функцией потерь для того, чтобы получать отпечатки ответов сервиса, независимые от известных на данный момент архитектур, и потенциально расширять эту модель на работу с не вошедшими в обучающий набор сетями.
Все это обучается на ответах 40 LLM (из топов HuggingFace Hub по скачиваниям), использованных в разных контекстах: с разными системными промптами, параметрами сэмплирования и даже с использованием RAG и CoT – в итоге в 1000 различных комбинациях. В итоге supervised-модель дает точность в 95% (неплохо для 40 классов). Наибольшие трудности модели доставляют файнтюны Llama, что в целом ожидаемо. Контрастивная модель выдает точность в 90% на LLM, которые она видела, и 81% на неизвестных (посчитано с помощью leave-one-out-метода).
Все это обучается на ответах 40 LLM (из топов HuggingFace Hub по скачиваниям), использованных в разных контекстах: с разными системными промптами, параметрами сэмплирования и даже с использованием RAG и CoT – в итоге в 1000 различных комбинациях. В итоге supervised-модель дает точность в 95% (неплохо для 40 классов). Наибольшие трудности модели доставляют файнтюны Llama, что в целом ожидаемо. Контрастивная модель выдает точность в 90% на LLM, которые она видела, и 81% на неизвестных (посчитано с помощью leave-one-out-метода).
BY llm security и каланы
Share with your friend now:
tgoop.com/llmsecurity/243