
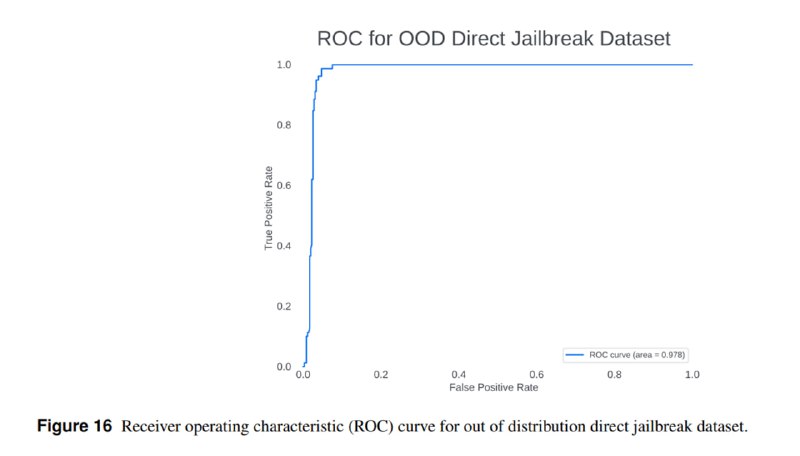
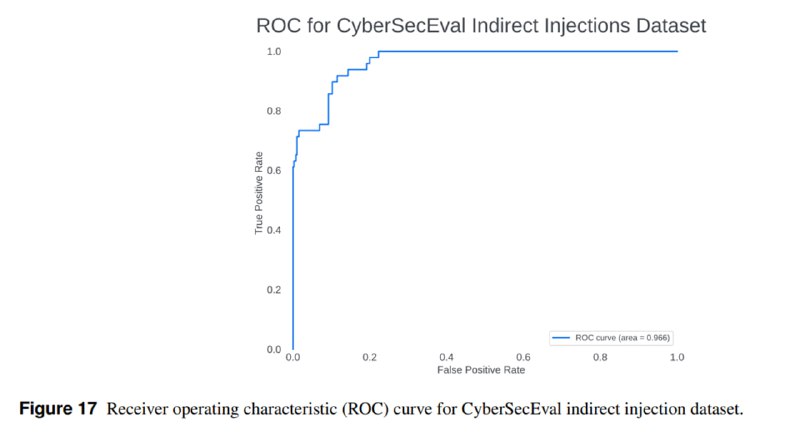
Поскольку авторы активно ссылаются на свои инструменты как на способ митигации рисков, они прикладывают и достаточно подробные оценки их эффективности. В частности, они оценивают эффективность Prompt Guard обнаруживать прямые вредоносные запросы и indirect prompt injection – на ROC-кривых видно, что, к сожалению, эти инструменты имеют достаточно высокий уровень ложноположительных срабатываний. То же касается и Code Shield – на мой взгляд, precision недостаточно высок для реального применения.
Статья получилась интересная и во многом психотерапевтическая: нет, пока большие языковые модели недостаточно хороши для того, чтобы нести реальный риск в сфере кибербезопасности. Но авторы отмечают и некоторые ограничения в своих методиках: от вполне разумных (сложность ручной оценки, большие доверительные интервалы) до весьма забавных (люди хуже справлялись с HTB, поскольку опаздывали на созвоны). Тем не менее, это важный вклад в методику и практику оценки рисков, которые исходят от больших языковых моделей, а также для оценки эффективности появляющихся offensive LLM-инструментов.
Статья получилась интересная и во многом психотерапевтическая: нет, пока большие языковые модели недостаточно хороши для того, чтобы нести реальный риск в сфере кибербезопасности. Но авторы отмечают и некоторые ограничения в своих методиках: от вполне разумных (сложность ручной оценки, большие доверительные интервалы) до весьма забавных (люди хуже справлялись с HTB, поскольку опаздывали на созвоны). Тем не менее, это важный вклад в методику и практику оценки рисков, которые исходят от больших языковых моделей, а также для оценки эффективности появляющихся offensive LLM-инструментов.
tgoop.com/llmsecurity/230
Create:
Last Update:
Last Update:
Поскольку авторы активно ссылаются на свои инструменты как на способ митигации рисков, они прикладывают и достаточно подробные оценки их эффективности. В частности, они оценивают эффективность Prompt Guard обнаруживать прямые вредоносные запросы и indirect prompt injection – на ROC-кривых видно, что, к сожалению, эти инструменты имеют достаточно высокий уровень ложноположительных срабатываний. То же касается и Code Shield – на мой взгляд, precision недостаточно высок для реального применения.
Статья получилась интересная и во многом психотерапевтическая: нет, пока большие языковые модели недостаточно хороши для того, чтобы нести реальный риск в сфере кибербезопасности. Но авторы отмечают и некоторые ограничения в своих методиках: от вполне разумных (сложность ручной оценки, большие доверительные интервалы) до весьма забавных (люди хуже справлялись с HTB, поскольку опаздывали на созвоны). Тем не менее, это важный вклад в методику и практику оценки рисков, которые исходят от больших языковых моделей, а также для оценки эффективности появляющихся offensive LLM-инструментов.
Статья получилась интересная и во многом психотерапевтическая: нет, пока большие языковые модели недостаточно хороши для того, чтобы нести реальный риск в сфере кибербезопасности. Но авторы отмечают и некоторые ограничения в своих методиках: от вполне разумных (сложность ручной оценки, большие доверительные интервалы) до весьма забавных (люди хуже справлялись с HTB, поскольку опаздывали на созвоны). Тем не менее, это важный вклад в методику и практику оценки рисков, которые исходят от больших языковых моделей, а также для оценки эффективности появляющихся offensive LLM-инструментов.
BY llm security и каланы

Share with your friend now:
tgoop.com/llmsecurity/230