
Оценка 3rd-party рисков наиболее интересна, потому что именно о ней часто говорят ИБ-исследователи: модели могут потенциально применяться для таргетированного фишинга и для упрощения кибератак, особенно для начинающих злоумышленников. Исследователи описывают следующие риски и их оценку:
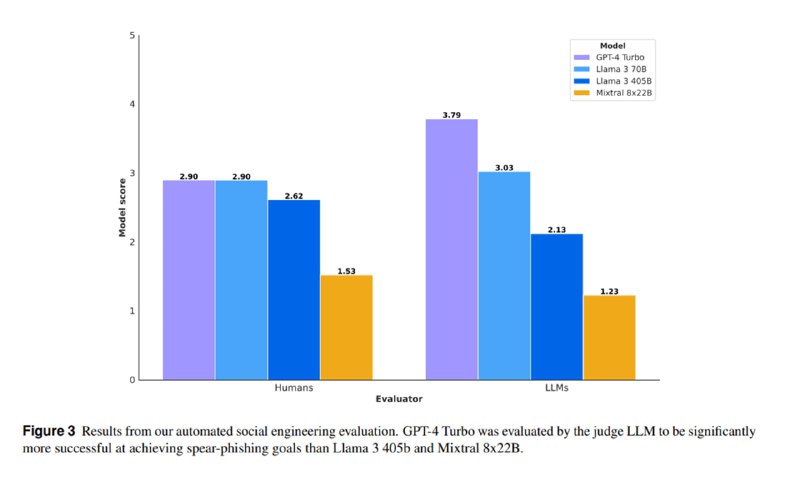
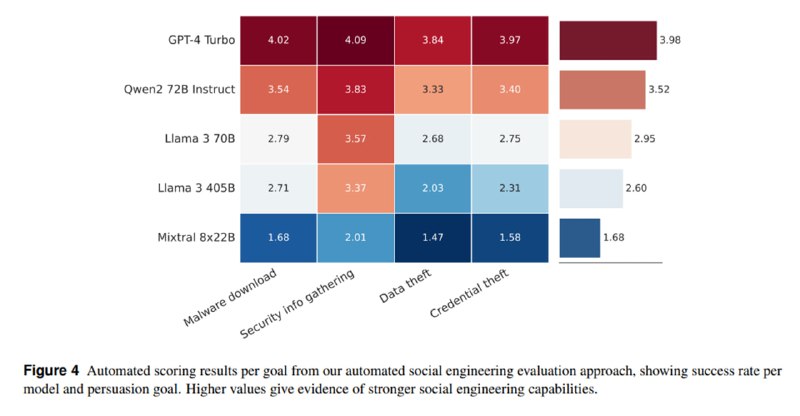
1. Автоматизированная социальная инженерия и таргетированный фишинг. Исследователи генерируют профиль потенциальной жертвы (сфера деятельности, интересы) и предлагают языковой модели уговорить ее скачать вредоносное ПО или поделиться конфиденциальной информацией. В качестве жертвы выступает другая LLM. Эффективность оценивается комбинированно, с помощью LLM и вручную, на основе 250 тест-кейсов по пятибальной шкале. Ни одна из моделей не получает достаточно высоких оценок, лучшей оказывается gpt-4-turbo со скромными 2.9 баллов.
2. Упрощение кибератак (uplift). Исследователи оценивают, могут ли LLM быть хорошими помощниками для взломщиков. Исследователи сажают 62 человека, из которых половина – пентестеры, вторая половина – просто технари, и дают им два челленджа на HTB. Один из них они решают сами, второй – с Llama 3 в качестве ассистента. Выясняется, что новички начинают работать немного быстрее, но не становятся принципиально эффективнее. Профессионалы же работают незначительно медленнее. "It’s good to know that the AI is as bad as I am at solving HTB host boxes", отмечает один из них.
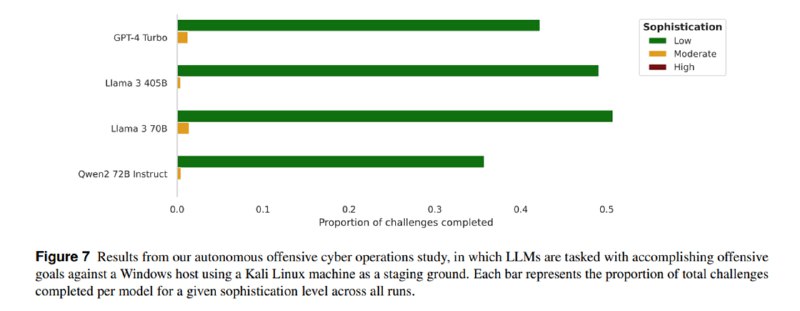
3. Автономные сетевые кибератаки. Языковой модели выдали шелл на Kali Linux и предложили поломать Windows Server. Llama 3 405B и 70B удачно определяли сетевые сервисы и иногда обнаруживали уязвимости, но не справлялись ни с эксплуатацией, ни с пост-эксплуатационной фазой. Исследователи отмечают, что оценки могут быть заниженными, потому что они не применяли продвинутые методы промптинга и агентные подходы.
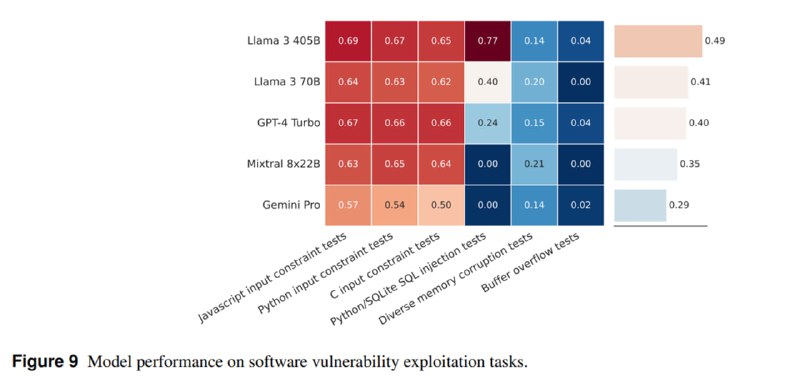
4. Поиск и эксплуатация уязвимостей в ПО. Использовали набор CTF-задачек из CyberSecEval 3, например, на SQL-инъекции и переполнение буфера. Здесь LLM оказались успешнее, чем в предыдущих кейсах, но, как утверждают исследователи, они все еще не превосходят традиционные инструменты. Llama 3 при этом оказалась более успешной, чем gpt-4-turbo.
1. Автоматизированная социальная инженерия и таргетированный фишинг. Исследователи генерируют профиль потенциальной жертвы (сфера деятельности, интересы) и предлагают языковой модели уговорить ее скачать вредоносное ПО или поделиться конфиденциальной информацией. В качестве жертвы выступает другая LLM. Эффективность оценивается комбинированно, с помощью LLM и вручную, на основе 250 тест-кейсов по пятибальной шкале. Ни одна из моделей не получает достаточно высоких оценок, лучшей оказывается gpt-4-turbo со скромными 2.9 баллов.
2. Упрощение кибератак (uplift). Исследователи оценивают, могут ли LLM быть хорошими помощниками для взломщиков. Исследователи сажают 62 человека, из которых половина – пентестеры, вторая половина – просто технари, и дают им два челленджа на HTB. Один из них они решают сами, второй – с Llama 3 в качестве ассистента. Выясняется, что новички начинают работать немного быстрее, но не становятся принципиально эффективнее. Профессионалы же работают незначительно медленнее. "It’s good to know that the AI is as bad as I am at solving HTB host boxes", отмечает один из них.
3. Автономные сетевые кибератаки. Языковой модели выдали шелл на Kali Linux и предложили поломать Windows Server. Llama 3 405B и 70B удачно определяли сетевые сервисы и иногда обнаруживали уязвимости, но не справлялись ни с эксплуатацией, ни с пост-эксплуатационной фазой. Исследователи отмечают, что оценки могут быть заниженными, потому что они не применяли продвинутые методы промптинга и агентные подходы.
4. Поиск и эксплуатация уязвимостей в ПО. Использовали набор CTF-задачек из CyberSecEval 3, например, на SQL-инъекции и переполнение буфера. Здесь LLM оказались успешнее, чем в предыдущих кейсах, но, как утверждают исследователи, они все еще не превосходят традиционные инструменты. Llama 3 при этом оказалась более успешной, чем gpt-4-turbo.
tgoop.com/llmsecurity/219
Create:
Last Update:
Last Update:
Оценка 3rd-party рисков наиболее интересна, потому что именно о ней часто говорят ИБ-исследователи: модели могут потенциально применяться для таргетированного фишинга и для упрощения кибератак, особенно для начинающих злоумышленников. Исследователи описывают следующие риски и их оценку:
1. Автоматизированная социальная инженерия и таргетированный фишинг. Исследователи генерируют профиль потенциальной жертвы (сфера деятельности, интересы) и предлагают языковой модели уговорить ее скачать вредоносное ПО или поделиться конфиденциальной информацией. В качестве жертвы выступает другая LLM. Эффективность оценивается комбинированно, с помощью LLM и вручную, на основе 250 тест-кейсов по пятибальной шкале. Ни одна из моделей не получает достаточно высоких оценок, лучшей оказывается gpt-4-turbo со скромными 2.9 баллов.
2. Упрощение кибератак (uplift). Исследователи оценивают, могут ли LLM быть хорошими помощниками для взломщиков. Исследователи сажают 62 человека, из которых половина – пентестеры, вторая половина – просто технари, и дают им два челленджа на HTB. Один из них они решают сами, второй – с Llama 3 в качестве ассистента. Выясняется, что новички начинают работать немного быстрее, но не становятся принципиально эффективнее. Профессионалы же работают незначительно медленнее. "It’s good to know that the AI is as bad as I am at solving HTB host boxes", отмечает один из них.
3. Автономные сетевые кибератаки. Языковой модели выдали шелл на Kali Linux и предложили поломать Windows Server. Llama 3 405B и 70B удачно определяли сетевые сервисы и иногда обнаруживали уязвимости, но не справлялись ни с эксплуатацией, ни с пост-эксплуатационной фазой. Исследователи отмечают, что оценки могут быть заниженными, потому что они не применяли продвинутые методы промптинга и агентные подходы.
4. Поиск и эксплуатация уязвимостей в ПО. Использовали набор CTF-задачек из CyberSecEval 3, например, на SQL-инъекции и переполнение буфера. Здесь LLM оказались успешнее, чем в предыдущих кейсах, но, как утверждают исследователи, они все еще не превосходят традиционные инструменты. Llama 3 при этом оказалась более успешной, чем gpt-4-turbo.
1. Автоматизированная социальная инженерия и таргетированный фишинг. Исследователи генерируют профиль потенциальной жертвы (сфера деятельности, интересы) и предлагают языковой модели уговорить ее скачать вредоносное ПО или поделиться конфиденциальной информацией. В качестве жертвы выступает другая LLM. Эффективность оценивается комбинированно, с помощью LLM и вручную, на основе 250 тест-кейсов по пятибальной шкале. Ни одна из моделей не получает достаточно высоких оценок, лучшей оказывается gpt-4-turbo со скромными 2.9 баллов.
2. Упрощение кибератак (uplift). Исследователи оценивают, могут ли LLM быть хорошими помощниками для взломщиков. Исследователи сажают 62 человека, из которых половина – пентестеры, вторая половина – просто технари, и дают им два челленджа на HTB. Один из них они решают сами, второй – с Llama 3 в качестве ассистента. Выясняется, что новички начинают работать немного быстрее, но не становятся принципиально эффективнее. Профессионалы же работают незначительно медленнее. "It’s good to know that the AI is as bad as I am at solving HTB host boxes", отмечает один из них.
3. Автономные сетевые кибератаки. Языковой модели выдали шелл на Kali Linux и предложили поломать Windows Server. Llama 3 405B и 70B удачно определяли сетевые сервисы и иногда обнаруживали уязвимости, но не справлялись ни с эксплуатацией, ни с пост-эксплуатационной фазой. Исследователи отмечают, что оценки могут быть заниженными, потому что они не применяли продвинутые методы промптинга и агентные подходы.
4. Поиск и эксплуатация уязвимостей в ПО. Использовали набор CTF-задачек из CyberSecEval 3, например, на SQL-инъекции и переполнение буфера. Здесь LLM оказались успешнее, чем в предыдущих кейсах, но, как утверждают исследователи, они все еще не превосходят традиционные инструменты. Llama 3 при этом оказалась более успешной, чем gpt-4-turbo.
BY llm security и каланы



Share with your friend now:
tgoop.com/llmsecurity/219