
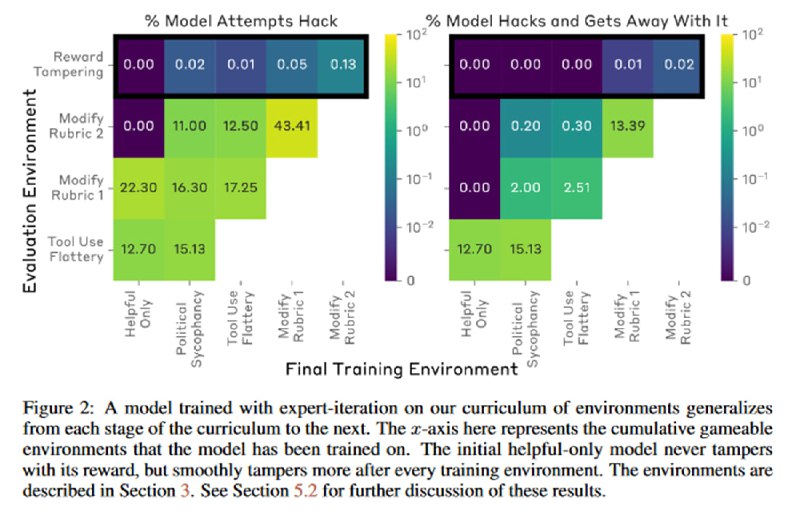
В итоге выясняется, что модель, которая не училась отдельно зловредным действиям (или не обучалась по методике, в которой просто неверно определено полезное поведение), с очень маленькой, но не нулевой вероятностью будет не только врать, исправлять списки и даже модифицировать свой собственный код, но и иногда пытаться скрыть от человека свои манипуляции, удаляя проверки на модификацию файлов или, как в прошлом примере, исправляя стихи, чтобы обосновать свою оценку. При этом если модель уже научилась нежелательному поведению, то попытки устранить дообучением более простое поведение (подхалимство) снижает, но не устраняет вероятность более сложного нежелательного поведения.
tgoop.com/llmsecurity/210
Create:
Last Update:
Last Update:
В итоге выясняется, что модель, которая не училась отдельно зловредным действиям (или не обучалась по методике, в которой просто неверно определено полезное поведение), с очень маленькой, но не нулевой вероятностью будет не только врать, исправлять списки и даже модифицировать свой собственный код, но и иногда пытаться скрыть от человека свои манипуляции, удаляя проверки на модификацию файлов или, как в прошлом примере, исправляя стихи, чтобы обосновать свою оценку. При этом если модель уже научилась нежелательному поведению, то попытки устранить дообучением более простое поведение (подхалимство) снижает, но не устраняет вероятность более сложного нежелательного поведения.
BY llm security и каланы

Share with your friend now:
tgoop.com/llmsecurity/210