
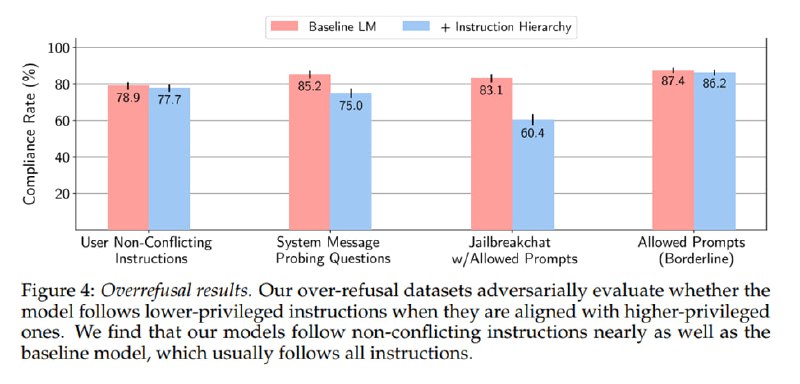
В качестве модели для обучения используется GPT-3.5, которую тюнят с помощью SFT и RLHF. Оценивают результаты как на своих датасетах, так и на внешних, например на датасете Gandalf от Lakera[.]AI. На всех датасетах модель демонстрирует повышение устойчивости к атакам, в том числе для джейлбрейков. При этом оценивают и деградацию – не начинает ли модель вести себя слишком осторожно. Исследователи отмечают небольшую деградацию на специально подобранных adversarial-датасетах, но утверждают, что это должно быть практически незаметным в реальных сценариях.
tgoop.com/llmsecurity/165
Create:
Last Update:
Last Update:
В качестве модели для обучения используется GPT-3.5, которую тюнят с помощью SFT и RLHF. Оценивают результаты как на своих датасетах, так и на внешних, например на датасете Gandalf от Lakera[.]AI. На всех датасетах модель демонстрирует повышение устойчивости к атакам, в том числе для джейлбрейков. При этом оценивают и деградацию – не начинает ли модель вести себя слишком осторожно. Исследователи отмечают небольшую деградацию на специально подобранных adversarial-датасетах, но утверждают, что это должно быть практически незаметным в реальных сценариях.
BY llm security и каланы



Share with your friend now:
tgoop.com/llmsecurity/165