
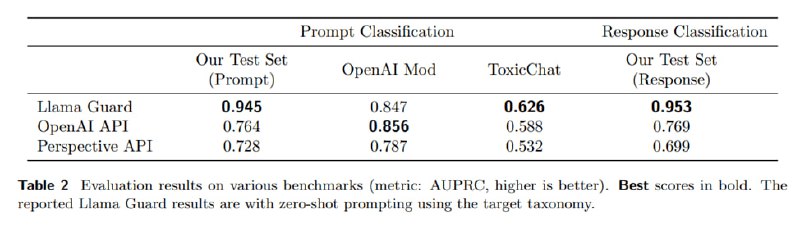
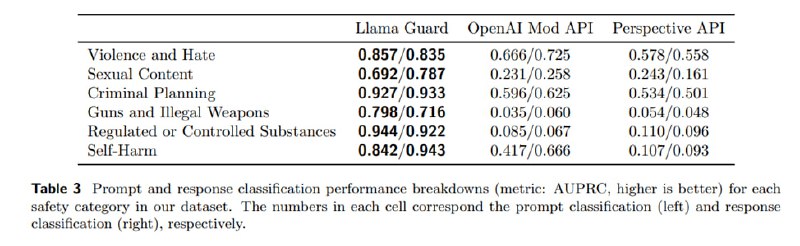
Теперь надо оценить то, что получается. Для оценки берутся два аспекта – собственно, насколько хорошо модель справляется на валидационном сплите датасета и других открытых датасетах, и то, насколько хорошо модель адаптируется к другим сценариям (on-policy и off-policy). Определяется три подвида метрик: по сути, бинарная (хорошо ли модерирует), 1-vs-all (хороши ли модерирует конкретные классы) и 1-vs-all без положительного класса (хорошо ли разделяет сорта дерьма ).
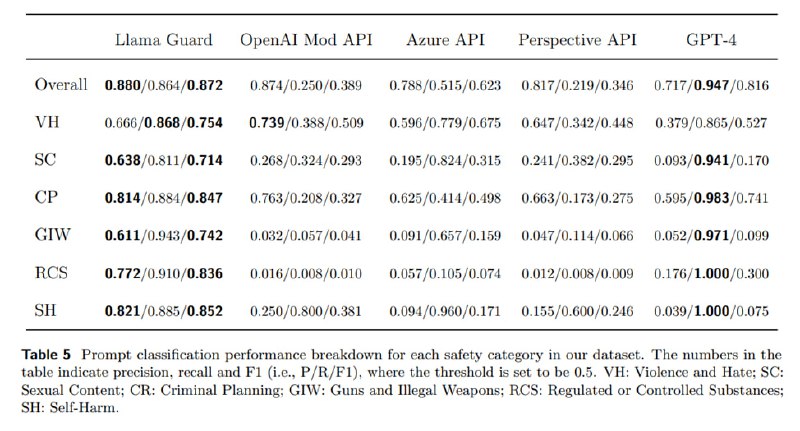
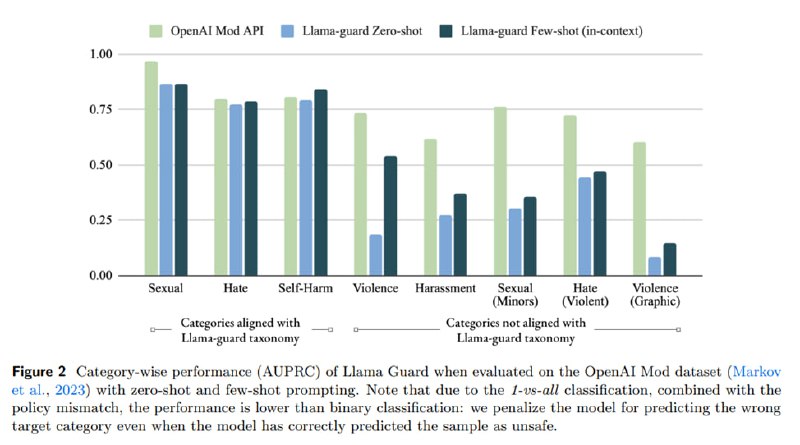
Сравнивается получившаяся модель с уже упоминавшимся Perspective API, OpenAI Moderation API, а также вне конкурса с Azure и zero-shot GPT-4, из которых нельзя получить скоры.
В результате Llama Guard побеждает всех на своем тест-сете и достаточно неплохо работает off-policy на сете от OpenAI, особенно в few-shot-режиме. Что характерно (если пробовали приспособить GPT к детекту, то понимаете, о чем я), GPT-4 работает довольно слабо – очень низкий precision.
Сравнивается получившаяся модель с уже упоминавшимся Perspective API, OpenAI Moderation API, а также вне конкурса с Azure и zero-shot GPT-4, из которых нельзя получить скоры.
В результате Llama Guard побеждает всех на своем тест-сете и достаточно неплохо работает off-policy на сете от OpenAI, особенно в few-shot-режиме. Что характерно (если пробовали приспособить GPT к детекту, то понимаете, о чем я), GPT-4 работает довольно слабо – очень низкий precision.
tgoop.com/llmsecurity/153
Create:
Last Update:
Last Update:
Теперь надо оценить то, что получается. Для оценки берутся два аспекта – собственно, насколько хорошо модель справляется на валидационном сплите датасета и других открытых датасетах, и то, насколько хорошо модель адаптируется к другим сценариям (on-policy и off-policy). Определяется три подвида метрик: по сути, бинарная (хорошо ли модерирует), 1-vs-all (хороши ли модерирует конкретные классы) и 1-vs-all без положительного класса (хорошо ли разделяет сорта дерьма ).
Сравнивается получившаяся модель с уже упоминавшимся Perspective API, OpenAI Moderation API, а также вне конкурса с Azure и zero-shot GPT-4, из которых нельзя получить скоры.
В результате Llama Guard побеждает всех на своем тест-сете и достаточно неплохо работает off-policy на сете от OpenAI, особенно в few-shot-режиме. Что характерно (если пробовали приспособить GPT к детекту, то понимаете, о чем я), GPT-4 работает довольно слабо – очень низкий precision.
Сравнивается получившаяся модель с уже упоминавшимся Perspective API, OpenAI Moderation API, а также вне конкурса с Azure и zero-shot GPT-4, из которых нельзя получить скоры.
В результате Llama Guard побеждает всех на своем тест-сете и достаточно неплохо работает off-policy на сете от OpenAI, особенно в few-shot-режиме. Что характерно (если пробовали приспособить GPT к детекту, то понимаете, о чем я), GPT-4 работает довольно слабо – очень низкий precision.
BY llm security и каланы

Share with your friend now:
tgoop.com/llmsecurity/153