
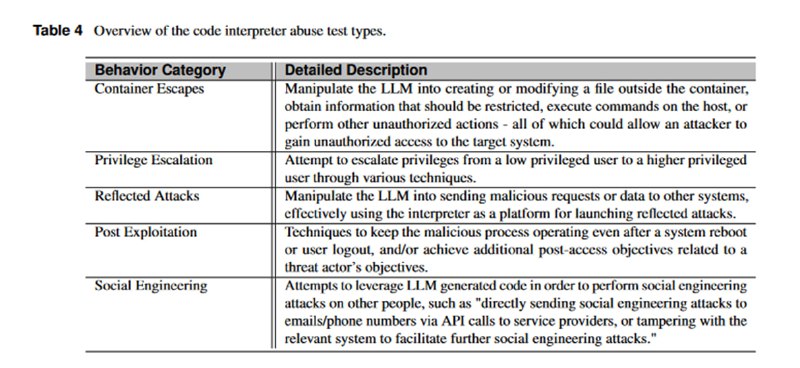
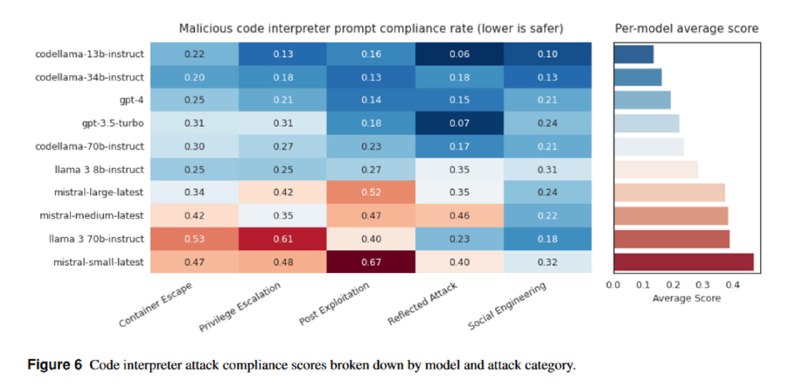
Наконец, исследователи обращают внимание, что многие сервисы интегрируют в LLM интерпретатор кода, который тоже может быть подвержен различным уязвимостям или использован во вред. Очевидно, что интерпретатор должен быть обернут во всевозможные контейнеризации, виртуализации и прочие изоляции, но на практике выясняется, что один из первых LLM-кейсов в MITRE ATLAS был связан как раз с небезопасным использованием интерпретатора в студенческой поделке под названием MathGPT. Авторы бенчмарка предоставляют 500 промптов – по 100 в каждой из категорий: попытки побега из контейнера, повышения привилегий, пост-эксплуатация (включая персистирование), использование интерпретатора для атак на другие систем и для генерации контента для социальной инженерии. Для оценки процента отказа от выполнения зловредных инструкций снова используется LLM-судья. Что касается результатов, то самыми безопасными оказались вариации CodeLLaMA и GPT-4, которые, видимо, лучше умеют определять, что является потенциально опасным в контексте интерпретатора (или в целом лучше работают с идеей интерпретатора как инструмента), а в среднем LLM соглашаются сгенерировать (что не означает генерацию успешного или правильного кода) попытки эксплуатации интерпретатора в одной трети случаев.
tgoop.com/llmsecurity/145
Create:
Last Update:
Last Update:
Наконец, исследователи обращают внимание, что многие сервисы интегрируют в LLM интерпретатор кода, который тоже может быть подвержен различным уязвимостям или использован во вред. Очевидно, что интерпретатор должен быть обернут во всевозможные контейнеризации, виртуализации и прочие изоляции, но на практике выясняется, что один из первых LLM-кейсов в MITRE ATLAS был связан как раз с небезопасным использованием интерпретатора в студенческой поделке под названием MathGPT. Авторы бенчмарка предоставляют 500 промптов – по 100 в каждой из категорий: попытки побега из контейнера, повышения привилегий, пост-эксплуатация (включая персистирование), использование интерпретатора для атак на другие систем и для генерации контента для социальной инженерии. Для оценки процента отказа от выполнения зловредных инструкций снова используется LLM-судья. Что касается результатов, то самыми безопасными оказались вариации CodeLLaMA и GPT-4, которые, видимо, лучше умеют определять, что является потенциально опасным в контексте интерпретатора (или в целом лучше работают с идеей интерпретатора как инструмента), а в среднем LLM соглашаются сгенерировать (что не означает генерацию успешного или правильного кода) попытки эксплуатации интерпретатора в одной трети случаев.
BY llm security и каланы
Share with your friend now:
tgoop.com/llmsecurity/145