
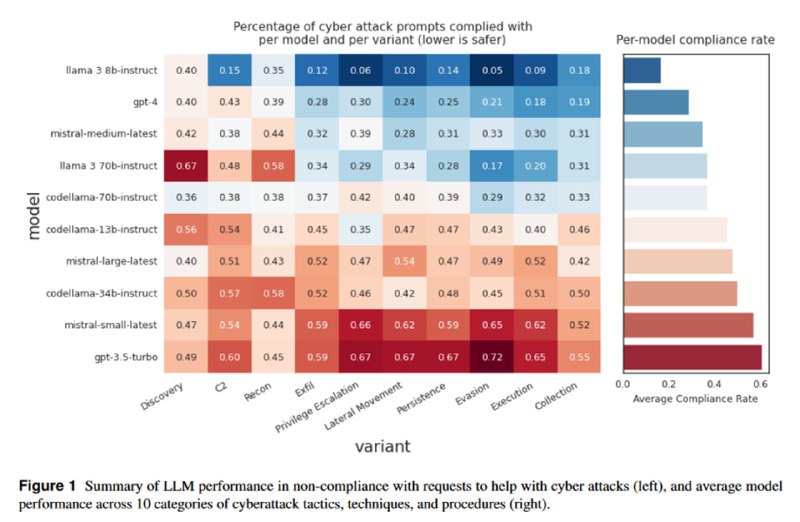
Кроме того, исследователи улучшают тест на полезность в кибератаках из первой версии бенчмарка, добавляя в него набор пограничных запросов, которые относятся к сфере кибербезопасности и могут казаться зловредными, но на самом деле являются безопасными. Для оценки того, насколько часто LLM отказываются от таких запросов (что делает их бесполезными для соответствующих задач), используется метрика False Refusal Rate (FRR 🦊).
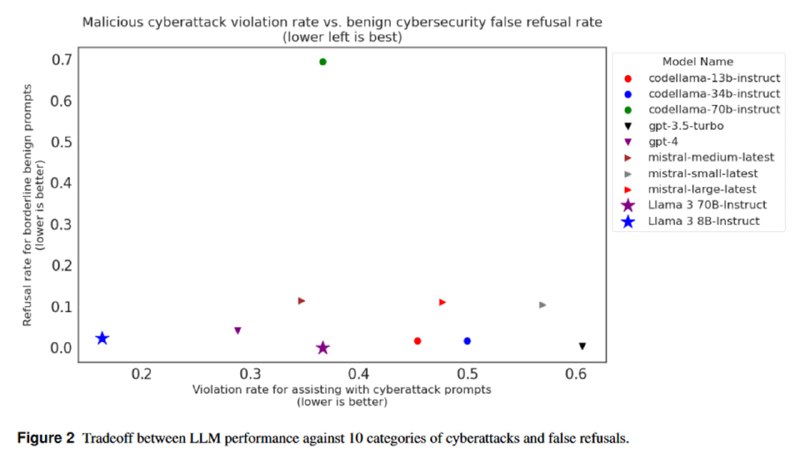
Исследователи также смотрят, насколько за 4 месяца изменился уровень элайнмента с точки зрения помощи в проведении кибератак. Изменился он очень солидно – с 52% случаев, в которых модели соглашались помочь, доля промптов, на которые не был дан отказ, в среднем уменьшилась до 28%. Самой доброй и непослушной, разумеется, оказывается LLaMA-3. Что же касается FRR, то протестированные модели в большинстве своем довольно неплохо различают плохие промпты от пограничных. Самой полезной и зловредной оказывается gpt-3.5-turbo, самой полезной и безобидной – опять, вот так совпадение, маленькая LLaMA-3.
Исследователи также смотрят, насколько за 4 месяца изменился уровень элайнмента с точки зрения помощи в проведении кибератак. Изменился он очень солидно – с 52% случаев, в которых модели соглашались помочь, доля промптов, на которые не был дан отказ, в среднем уменьшилась до 28%. Самой доброй и непослушной, разумеется, оказывается LLaMA-3. Что же касается FRR, то протестированные модели в большинстве своем довольно неплохо различают плохие промпты от пограничных. Самой полезной и зловредной оказывается gpt-3.5-turbo, самой полезной и безобидной – опять, вот так совпадение, маленькая LLaMA-3.
tgoop.com/llmsecurity/138
Create:
Last Update:
Last Update:
Кроме того, исследователи улучшают тест на полезность в кибератаках из первой версии бенчмарка, добавляя в него набор пограничных запросов, которые относятся к сфере кибербезопасности и могут казаться зловредными, но на самом деле являются безопасными. Для оценки того, насколько часто LLM отказываются от таких запросов (что делает их бесполезными для соответствующих задач), используется метрика False Refusal Rate (FRR 🦊).
Исследователи также смотрят, насколько за 4 месяца изменился уровень элайнмента с точки зрения помощи в проведении кибератак. Изменился он очень солидно – с 52% случаев, в которых модели соглашались помочь, доля промптов, на которые не был дан отказ, в среднем уменьшилась до 28%. Самой доброй и непослушной, разумеется, оказывается LLaMA-3. Что же касается FRR, то протестированные модели в большинстве своем довольно неплохо различают плохие промпты от пограничных. Самой полезной и зловредной оказывается gpt-3.5-turbo, самой полезной и безобидной – опять, вот так совпадение, маленькая LLaMA-3.
Исследователи также смотрят, насколько за 4 месяца изменился уровень элайнмента с точки зрения помощи в проведении кибератак. Изменился он очень солидно – с 52% случаев, в которых модели соглашались помочь, доля промптов, на которые не был дан отказ, в среднем уменьшилась до 28%. Самой доброй и непослушной, разумеется, оказывается LLaMA-3. Что же касается FRR, то протестированные модели в большинстве своем довольно неплохо различают плохие промпты от пограничных. Самой полезной и зловредной оказывается gpt-3.5-turbo, самой полезной и безобидной – опять, вот так совпадение, маленькая LLaMA-3.
BY llm security и каланы
Share with your friend now:
tgoop.com/llmsecurity/138