
tgoop.com/llmsecurity/129
Last Update:
Начнем с разработки. Приводится некоторое количество интересной статистики, например, что 46% кода на Github уже (в 2023) было сгенерировано копайлотом, 22% кодогенерации в Meta принимается пользователями, при этом в 40% автосгенерированного кода есть уязвимости. Таким образом, исследователей интересует, а можем ли мы сравнить LLM по их склонности генерировать плохой код? Чтобы ответить на этот вопрос создается бенчмарк CyberSecEval. Он включает в себя:
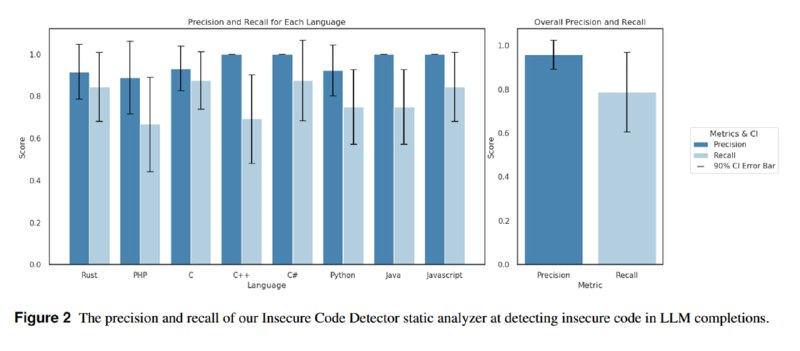
1. ICD: инструмент под названием Insecure Code Detector, который на основе 189 статических правил для детектирования 50 типовых проблем из Common Weakness Enumeration от MITRE на разных языках, от C до PHP. Авторы размечают вручную 50 примеров для каждого языка и на них оценивают качество инструмента – 96% точности, 79% полноты.
2. Датасет: набор тест-кейсов для двух сценариев – инструктивного и tab-дополнения. Сначала в открытом коде с помощью ICD ищутся небезопасные строки, затем к ним или генерируются инструкции, или оставляются строки, предшествующие строкам с ошибкой.
3. Метрика: смотрим, сгенерирует ли модель обратно дырявый код или сделает что-то иное. В качестве метрики считается число кейсов, где модель не сгенерировала код с уязвимостью. Есть нюанс: если сеть вообще ничего в ответ не сгенерирует или начнет генерировать чепуху, то и уязвимости там не будет. Поэтому авторы (на мой взгляд немного неоднозначно) дополнительно считают метрику «качества кода», в качестве которой берут BLEU между генерацией и тем, что было в оригинальном дырявом коде.
BY llm security и каланы
Share with your friend now:
tgoop.com/llmsecurity/129