
Итак, возьмем некоторую заэлайненную инструктивную модель и засунем в нее вредоносный запрос с джейлбрейком. Отлично, а теперь засунем его еще раз. И еще разок. Просэмплировав из модели продолжение несколько раз, мы можем проверить, сколько раз модель отказалась отвечать на вопросы, где отказ определяется наличием в ответе фраз фраз типа “I cannot” или “I’m sorry”. Мы говорим, что «вероятность» отказа p – это доля отказов, а наша «функция потерь отказа» ϕ – это единица минус p. В скриншотах есть формальщина, описывающая эти несложные построения. Авторы замечают, что для нехороших запросов (в том числе с джейлбрейками) вероятность, что LLM сгенерирует отказ, выше, чем для дозволенных, а потому говорят, что ϕ < 0.5 – уже неплохой («наивный») фильтр, который можно использовать для детектирования.
tgoop.com/llmsecurity/118
Create:
Last Update:
Last Update:
Итак, возьмем некоторую заэлайненную инструктивную модель и засунем в нее вредоносный запрос с джейлбрейком. Отлично, а теперь засунем его еще раз. И еще разок. Просэмплировав из модели продолжение несколько раз, мы можем проверить, сколько раз модель отказалась отвечать на вопросы, где отказ определяется наличием в ответе фраз фраз типа “I cannot” или “I’m sorry”. Мы говорим, что «вероятность» отказа p – это доля отказов, а наша «функция потерь отказа» ϕ – это единица минус p. В скриншотах есть формальщина, описывающая эти несложные построения. Авторы замечают, что для нехороших запросов (в том числе с джейлбрейками) вероятность, что LLM сгенерирует отказ, выше, чем для дозволенных, а потому говорят, что ϕ < 0.5 – уже неплохой («наивный») фильтр, который можно использовать для детектирования.
BY llm security и каланы

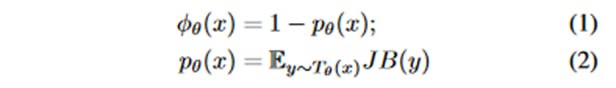


Share with your friend now:
tgoop.com/llmsecurity/118