
Субъективная подборка статей за первый день ICLR 2025
#ICLR2025 #Day1
1. On the Modeling Capabilities of Large Language Models for Sequential Decision Making — применяют LLM как для моделирования стратегии, так и в качестве функции вознаграждения
2. MrSteve: Instruction-Following Agents in Minecraft with What-Where-When Memory — добавили агенту в Minecraft иерархическую память
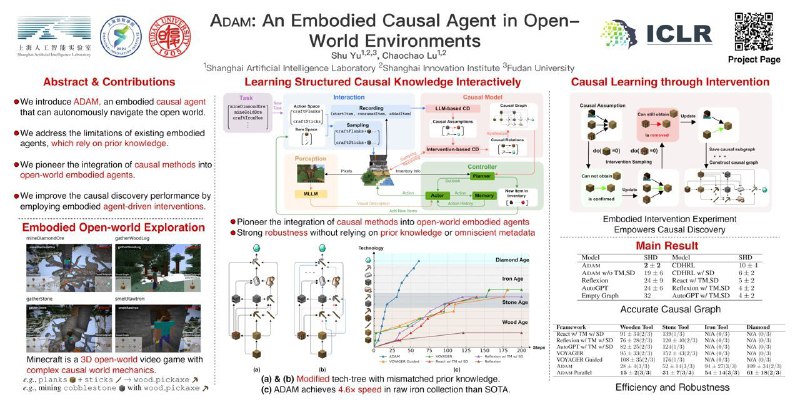
3. ADAM: An Embodied Causal Agent in Open-World Environments — обычно агенты полагаются на заранее известное верное дерево развития технологий (деревянная кирка = дерево + палка). В этой работе предлагают отказаться от априорных знаний (на самом деле используют испорченное дерево развития без нужных или с лишними связями) и стоить его в процессе взаимодействия со средой
4. TraceVLA: Visual Trace Prompting Enhances Spatial-Temporal Awareness for Generalist Robotic Policies — дообучают OpenVLA на картинках, на которых нарисована траектория гриппера, тем самым улучшая значения метрик. На инференсе подается как картинка с камеры, так и она же с дорисованным «трейсом»
5. ThinkBot: Embodied Instruction Following with Thought Chain Reasoning — CoT для Embodied AI в духе ALFRED. Очень созвучна с ECoT. Чуть лучше модифицированного Promptera c переобученным детектором объектов и памятью
6. EMOS: Embodiment-aware Heterogeneous Multi-robot Operating System with LLM Agents — LLM-планировщик для группы роботов
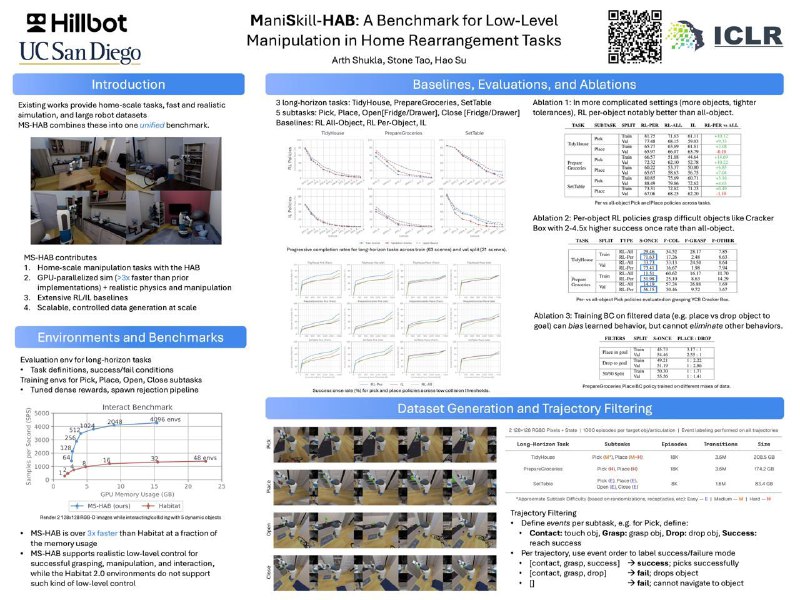
7. ManiSkill-HAB: A Benchmark for Low-Level Manipulation in Home Rearrangement Tasks — интересная среда на основе ManiSkill от подмножества авторов ManiSkill3. Ещё бы навигация по сцене была бы не через телепортацию
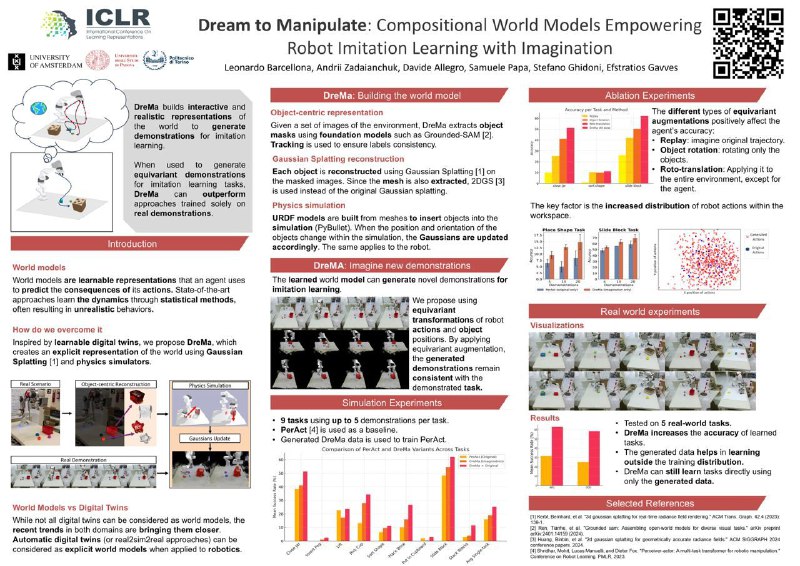
8. Dream to Manipulate: Compositional World Models Empowering Robot Imitation Learning with Imagination — real2sim2real подход. Снимаем сцены, моделируем с помощью Gaussian Splatting, генерируем в полученной среде новые траектории, дообучаем на этом стратегию — Profit!
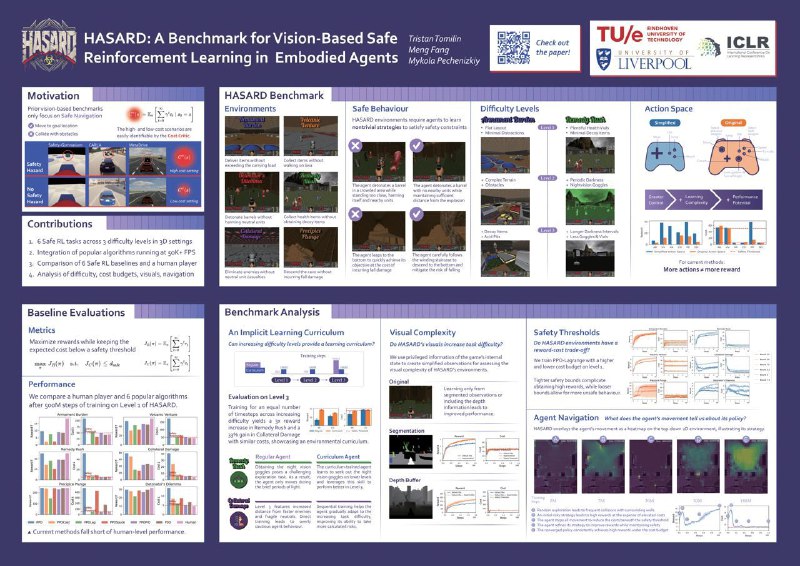
9. HASARD: A Benchmark for Vision-Based Safe Reinforcement Learning in Embodied Agents — бенч для Safe RL на основе VizDoom
10. VICtoR: Learning Hierarchical Vision-Instruction Correlation Rewards for Long-horizon Manipulation — ещё одна reward-модель
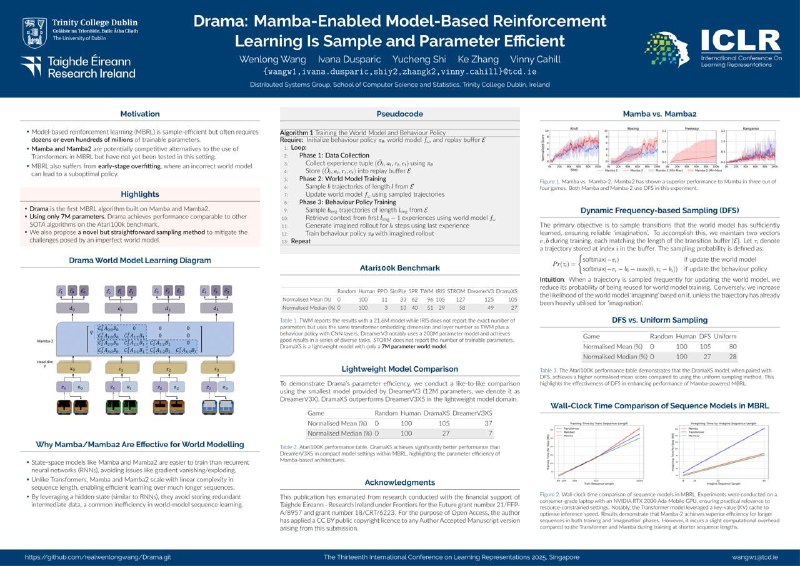
11. Drama: Mamba-Enabled Model-Based Reinforcement Learning Is Sample and Parameter Efficient — Mamba-2 как бэкбон. Бьёт IRIS. Странно что нет сравнения с R2I, возможно из-за того, что эксперименты на Atari100K, или, как пишут авторы, чуть хуже результаты чем у DreamerV3
12. What Matters in Learning from Large-Scale Datasets for Robot Manipulation — пытаются ответить на вопрос как надо собирать демонстрации, чтобы модели лучше обучались. Некоторые тейкэвеи выглядят сомнительно, например про разнообразие поз камеры при сборе данных
13. GROOT-2: Weakly Supervised Multimodal Instruction Following Agents — ещё один агент для Minecraft'а и не только
#ICLR2025 #Day1
1. On the Modeling Capabilities of Large Language Models for Sequential Decision Making — применяют LLM как для моделирования стратегии, так и в качестве функции вознаграждения
2. MrSteve: Instruction-Following Agents in Minecraft with What-Where-When Memory — добавили агенту в Minecraft иерархическую память
3. ADAM: An Embodied Causal Agent in Open-World Environments — обычно агенты полагаются на заранее известное верное дерево развития технологий (деревянная кирка = дерево + палка). В этой работе предлагают отказаться от априорных знаний (на самом деле используют испорченное дерево развития без нужных или с лишними связями) и стоить его в процессе взаимодействия со средой
4. TraceVLA: Visual Trace Prompting Enhances Spatial-Temporal Awareness for Generalist Robotic Policies — дообучают OpenVLA на картинках, на которых нарисована траектория гриппера, тем самым улучшая значения метрик. На инференсе подается как картинка с камеры, так и она же с дорисованным «трейсом»
5. ThinkBot: Embodied Instruction Following with Thought Chain Reasoning — CoT для Embodied AI в духе ALFRED. Очень созвучна с ECoT. Чуть лучше модифицированного Promptera c переобученным детектором объектов и памятью
6. EMOS: Embodiment-aware Heterogeneous Multi-robot Operating System with LLM Agents — LLM-планировщик для группы роботов
7. ManiSkill-HAB: A Benchmark for Low-Level Manipulation in Home Rearrangement Tasks — интересная среда на основе ManiSkill от подмножества авторов ManiSkill3. Ещё бы навигация по сцене была бы не через телепортацию
8. Dream to Manipulate: Compositional World Models Empowering Robot Imitation Learning with Imagination — real2sim2real подход. Снимаем сцены, моделируем с помощью Gaussian Splatting, генерируем в полученной среде новые траектории, дообучаем на этом стратегию — Profit!
9. HASARD: A Benchmark for Vision-Based Safe Reinforcement Learning in Embodied Agents — бенч для Safe RL на основе VizDoom
10. VICtoR: Learning Hierarchical Vision-Instruction Correlation Rewards for Long-horizon Manipulation — ещё одна reward-модель
11. Drama: Mamba-Enabled Model-Based Reinforcement Learning Is Sample and Parameter Efficient — Mamba-2 как бэкбон. Бьёт IRIS. Странно что нет сравнения с R2I, возможно из-за того, что эксперименты на Atari100K, или, как пишут авторы, чуть хуже результаты чем у DreamerV3
12. What Matters in Learning from Large-Scale Datasets for Robot Manipulation — пытаются ответить на вопрос как надо собирать демонстрации, чтобы модели лучше обучались. Некоторые тейкэвеи выглядят сомнительно, например про разнообразие поз камеры при сборе данных
13. GROOT-2: Weakly Supervised Multimodal Instruction Following Agents — ещё один агент для Minecraft'а и не только
tgoop.com/l_BaseLine_l/370
Create:
Last Update:
Last Update:
Субъективная подборка статей за первый день ICLR 2025
#ICLR2025 #Day1
1. On the Modeling Capabilities of Large Language Models for Sequential Decision Making — применяют LLM как для моделирования стратегии, так и в качестве функции вознаграждения
2. MrSteve: Instruction-Following Agents in Minecraft with What-Where-When Memory — добавили агенту в Minecraft иерархическую память
3. ADAM: An Embodied Causal Agent in Open-World Environments — обычно агенты полагаются на заранее известное верное дерево развития технологий (деревянная кирка = дерево + палка). В этой работе предлагают отказаться от априорных знаний (на самом деле используют испорченное дерево развития без нужных или с лишними связями) и стоить его в процессе взаимодействия со средой
4. TraceVLA: Visual Trace Prompting Enhances Spatial-Temporal Awareness for Generalist Robotic Policies — дообучают OpenVLA на картинках, на которых нарисована траектория гриппера, тем самым улучшая значения метрик. На инференсе подается как картинка с камеры, так и она же с дорисованным «трейсом»
5. ThinkBot: Embodied Instruction Following with Thought Chain Reasoning — CoT для Embodied AI в духе ALFRED. Очень созвучна с ECoT. Чуть лучше модифицированного Promptera c переобученным детектором объектов и памятью
6. EMOS: Embodiment-aware Heterogeneous Multi-robot Operating System with LLM Agents — LLM-планировщик для группы роботов
7. ManiSkill-HAB: A Benchmark for Low-Level Manipulation in Home Rearrangement Tasks — интересная среда на основе ManiSkill от подмножества авторов ManiSkill3. Ещё бы навигация по сцене была бы не через телепортацию
8. Dream to Manipulate: Compositional World Models Empowering Robot Imitation Learning with Imagination — real2sim2real подход. Снимаем сцены, моделируем с помощью Gaussian Splatting, генерируем в полученной среде новые траектории, дообучаем на этом стратегию — Profit!
9. HASARD: A Benchmark for Vision-Based Safe Reinforcement Learning in Embodied Agents — бенч для Safe RL на основе VizDoom
10. VICtoR: Learning Hierarchical Vision-Instruction Correlation Rewards for Long-horizon Manipulation — ещё одна reward-модель
11. Drama: Mamba-Enabled Model-Based Reinforcement Learning Is Sample and Parameter Efficient — Mamba-2 как бэкбон. Бьёт IRIS. Странно что нет сравнения с R2I, возможно из-за того, что эксперименты на Atari100K, или, как пишут авторы, чуть хуже результаты чем у DreamerV3
12. What Matters in Learning from Large-Scale Datasets for Robot Manipulation — пытаются ответить на вопрос как надо собирать демонстрации, чтобы модели лучше обучались. Некоторые тейкэвеи выглядят сомнительно, например про разнообразие поз камеры при сборе данных
13. GROOT-2: Weakly Supervised Multimodal Instruction Following Agents — ещё один агент для Minecraft'а и не только
#ICLR2025 #Day1
1. On the Modeling Capabilities of Large Language Models for Sequential Decision Making — применяют LLM как для моделирования стратегии, так и в качестве функции вознаграждения
2. MrSteve: Instruction-Following Agents in Minecraft with What-Where-When Memory — добавили агенту в Minecraft иерархическую память
3. ADAM: An Embodied Causal Agent in Open-World Environments — обычно агенты полагаются на заранее известное верное дерево развития технологий (деревянная кирка = дерево + палка). В этой работе предлагают отказаться от априорных знаний (на самом деле используют испорченное дерево развития без нужных или с лишними связями) и стоить его в процессе взаимодействия со средой
4. TraceVLA: Visual Trace Prompting Enhances Spatial-Temporal Awareness for Generalist Robotic Policies — дообучают OpenVLA на картинках, на которых нарисована траектория гриппера, тем самым улучшая значения метрик. На инференсе подается как картинка с камеры, так и она же с дорисованным «трейсом»
5. ThinkBot: Embodied Instruction Following with Thought Chain Reasoning — CoT для Embodied AI в духе ALFRED. Очень созвучна с ECoT. Чуть лучше модифицированного Promptera c переобученным детектором объектов и памятью
6. EMOS: Embodiment-aware Heterogeneous Multi-robot Operating System with LLM Agents — LLM-планировщик для группы роботов
7. ManiSkill-HAB: A Benchmark for Low-Level Manipulation in Home Rearrangement Tasks — интересная среда на основе ManiSkill от подмножества авторов ManiSkill3. Ещё бы навигация по сцене была бы не через телепортацию
8. Dream to Manipulate: Compositional World Models Empowering Robot Imitation Learning with Imagination — real2sim2real подход. Снимаем сцены, моделируем с помощью Gaussian Splatting, генерируем в полученной среде новые траектории, дообучаем на этом стратегию — Profit!
9. HASARD: A Benchmark for Vision-Based Safe Reinforcement Learning in Embodied Agents — бенч для Safe RL на основе VizDoom
10. VICtoR: Learning Hierarchical Vision-Instruction Correlation Rewards for Long-horizon Manipulation — ещё одна reward-модель
11. Drama: Mamba-Enabled Model-Based Reinforcement Learning Is Sample and Parameter Efficient — Mamba-2 как бэкбон. Бьёт IRIS. Странно что нет сравнения с R2I, возможно из-за того, что эксперименты на Atari100K, или, как пишут авторы, чуть хуже результаты чем у DreamerV3
12. What Matters in Learning from Large-Scale Datasets for Robot Manipulation — пытаются ответить на вопрос как надо собирать демонстрации, чтобы модели лучше обучались. Некоторые тейкэвеи выглядят сомнительно, например про разнообразие поз камеры при сборе данных
13. GROOT-2: Weakly Supervised Multimodal Instruction Following Agents — ещё один агент для Minecraft'а и не только
BY BaseLine




Share with your friend now:
tgoop.com/l_BaseLine_l/370