
tgoop.com/knowledge_accumulator/202
Last Update:
Reward is Enough [2021] - манифест Дэвида Сильвера
Ключевой автор AlphaGo и соавтор многих прорывных RL-статей от Deepmind три года назад вместе с Ричардом Саттоном написал статью о том, каким он видит место награды в вопросах AI.
Главный посыл данной работы таков: наличие награды, как единственного вида сигнала, достаточно для получения любого типа поведения у системы.
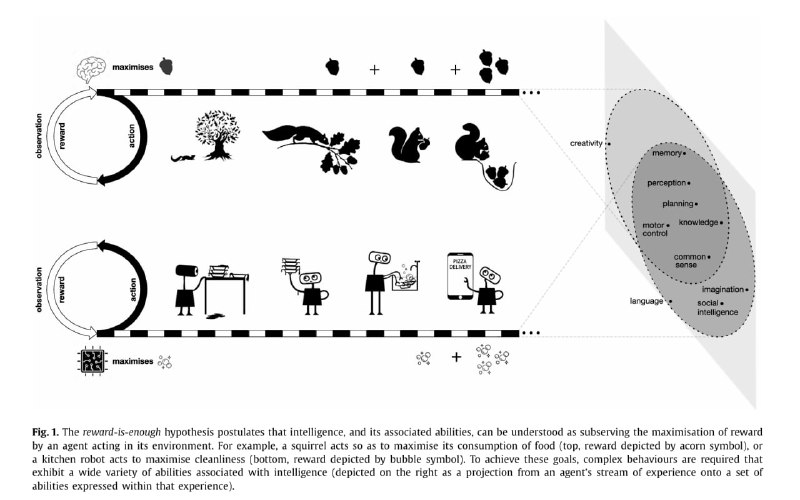
Авторы в качестве примера рассматривают бЕлок. Можно считать, что у неё есть единственная награда и цель - это количество накопленных орехов. Для того, чтобы накапливать орехи, ей нужно выработать много вспомогательных навыков - замечать орехи (perception), отличать нужные орехи (knowledge), собирать орехи (motor control), сберегать орехи (планирование и память).
AlphaGo, чтобы получить простую награду в виде выигрыша, в ходе обучения сама приобретает все необходимые умения для игры в Го. Гипотетический робот, которого мы хотим научить убирать кухню, также, как и белка, может научиться всему необходимому самостоятельно, максимизируя свою финальную награду.
С тем, что этого хватит для решения более сложных задач, согласны не все. В своём собственном манифесте (про JEPA) Ян ЛеКун называет один из разделов Reward is not enough. Здесь он воюет с соломенным чучелом, говоря, что model-free RL слишком неэффективен в использовании данных, так как награда - это очень ограниченный поток информации, и нужно искать способ извлекать информацию о мире из траекторий (например, как в SPR).
Но Silver и не утверждает, что текущие типы методов приведут к AGI. Его поинт в том, что нам не нужно явно ставить перед моделью какие-либо другие задачи, кроме максимизации награды. Даже general intelligence можно получить, обучая агента задачам, отличающимся достаточно сильно, чтобы модели было выгоднее выучить обучаемость, что и есть general intelligence. Здесь его интуиция в точности совпадает с моей - если в модель не влезают все задачи, она должна выучить способ учиться на ходу.
При этом всё необходимое - планирование, обучение world model и т.д. не нужно запихивать в модель в явном виде. Она сама будет выжимать максимум из имеющейся информации для максимизации своей награды. Даже, наверное, выучит какую-нибудь ЖЕПУ в неявном виде.
Из этой логики сразу же вытекают идеи мета-обучения RL-алгоритма на максимизацию награды, но в тот момент таких работ ещё совсем не было. Надеюсь, Дэвида отпустят из плена Gemini заниматься полезным ресёрчем.
Становится наглядным разделение людей на 3 лагеря - "Просто отмасштабируем текущие методы" имени Суцкевера, "Текущие методы говно, давайте придумаем получше" имени ЛеКуна и "Давайте обучать end-to-end на награду" имени Сильвера, Саттона и, конечно же, меня. К сожалению, первые 2 лагеря ещё не выучили горький урок от нашего с Сильвером товарища.
@knowledge_accumulator
BY Knowledge Accumulator
Share with your friend now:
tgoop.com/knowledge_accumulator/202