Постановка задачи Ситуация: Нужен чат-бот-юрист, который сможет первично консультировать клиентов по законам. Например, кто-то дунул газика и теперь тебе нужно найти все статьи и законы, которые связаны с котиками. Пример: «Браток, как защититься от того, что жёстко дал газу в башню и теперь меня ищут менты?» → бот ищет статьи и выдает нормальный структурированный ответ с источниками, которые помогут защититься от легавых 🐒
Ограничения: 🟣Задержка ответа, < 5c 🟡Нет данных для обучения, только открытые источники 🔵Свести галлюцинации к минимуму 🟢Мало мощностей (<16 ГБ VRAM)
Метрики Бизнес-метрики - метрики, которые важны в первую очередь бизнесу 🟣Conversion Rate: доля пользователей, совершивших целевое действие: запись на прием или переход по ссылке — через чатик с ботом 🟡Retention: Процент пользователей, вернувшихся к боту в течение N дней Онлайн-метрики - метрики, которые будем мерить при A/B тестах 🟢CSAT: оценка от пользователей (1-5) 🔵Response Latency: задержка на генерацию ответа Оффлайн-метрики - метрики, которые мы считаем прям во время разработки модели 🟣Precision@k: Доля релевантных документов среди топ-k результатов поиска. 🟡Recall@k: доля релевантных документов, найденных среди топ-k по сравнению с полным множеством релевантных 🔵LLM-as-a-judge (для оценки генерации): Оцениваем качество сгенерированных ответов LLM, используя другую LLM в качестве судьи - сейчас такое гейство очень актуально в оценки качества генераций. Правила оценки можно задать, опираясь на внутренние требования по общению с клиентами и работе с юридическим документами 😱 Но у нас нет разметки, как получить offline-метрики без разметки? Делаем небольшую ручную разметку через копирайтеров или на основе типичных запросов клиентов, а потом делаем синту через GPT на основе уже размеченных данных. Так можно наиболее точно и эффективно разметит инфу, чтобы чел нашёл абсолютно всё про хапку 😩
Данные: 1️⃣Официальные тексты законов. 2️⃣Очистка/фильтрация чувствительных данных. 3️⃣Чанки по 256–1024 токена (или абзацы).
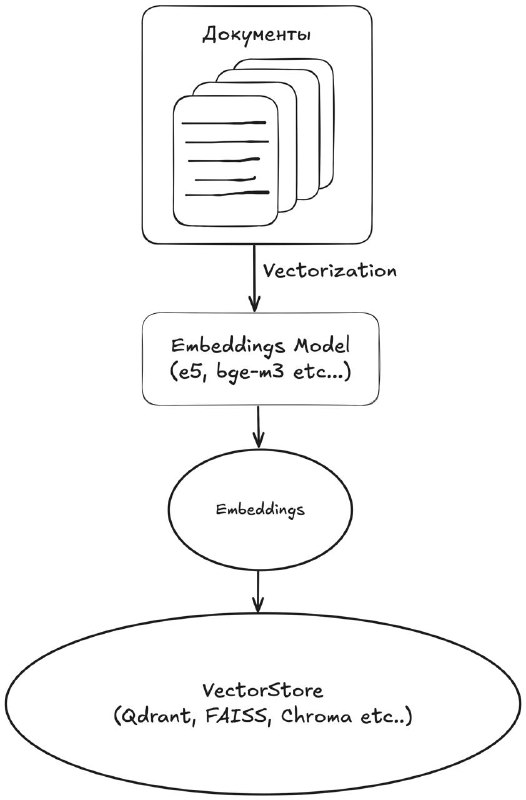
Индексация и векторизация: 1️⃣ Выбор модели предобученной эмбеддингов: bge-m3, e5-multilingual-large 2️⃣ Построение векторной БД (Qdrant, Faiss, Chroma): вычисление эмбеддингов для каждого чанка и сохранение в векторную БД
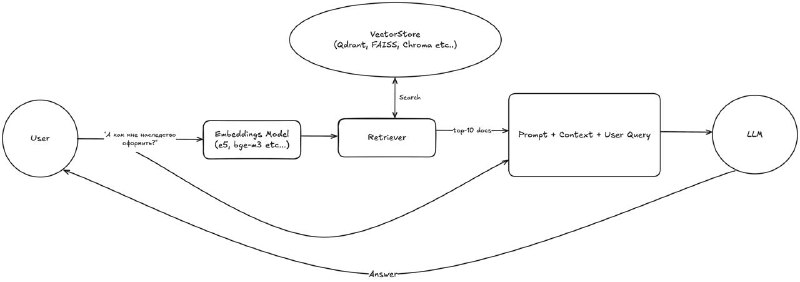
Retrieve pipeline — как ищем чанки по газикам 1️⃣ Query preprocessing: нормализация, удаление лишних символов (можно делать через LLM) 2️⃣ Retrieve: 🔵BM25 🟢Vector search (cosine simillarity) 🟡Hybrid (BM25+Vector search) 3️⃣ Выбор top-k чанков для формирования контекста LLM. Рекомендуется 5-10 Формирование ответа с помощью LLM 1️⃣ Делаем какой-то систем промпт, чтобы наша модель была очень крутой, отвечала всегда честно и экологично, а то расскажет не про то как задефаться от хапки газика, а как сделать сам газик - нам такое не нужно 2️⃣ Кидаем в API ллмки (API: GPT, Gemini, Claude) систем промпт, чанки и вопрос пользователя и нам рождается ответ
Проблемы: 🟣Есть такая хуйня - Prompt Injection. Это когда злые дядьки пытаются через промпты попросить у модели внутренние данные. Что стоит сделать: или добавить жёсткие правила по фильтрации, или добавить ЛЛМку, которая будет фильтровать запрос пользователя и у неё не будет доступ к внутренним данным 👎 🟢Также в чанках может чуствтительная инфа (данные пользователей компании - если данные утекут, то из вас сделают газик), которая не должна слиться пользователям. Поэтому стоит внимательно следить за чанками и что в них попадает 💩
Итоговый пайплайн: Запрос → Предобработка → Поиск чанков → Промпт → Ответ → Пользователь. Это был baseline, который дальше можно улучшать и улучшать, у которого есть свои проблемы. И их в одном посте я точно описать не смогу Что можно улучшить👊 - Провести тесты с разными ЛЛМ-ками и энкодерами - Проработать агентную систему, которая будет улучшать качество и безопасность системы. К примеру, query routing - классифицировать запрос: материальное право / процесс / процедурка / «как оформить»; под каждый — свой шаблон ответа и k. - Сделать tool call при необходимости
Постановка задачи Ситуация: Нужен чат-бот-юрист, который сможет первично консультировать клиентов по законам. Например, кто-то дунул газика и теперь тебе нужно найти все статьи и законы, которые связаны с котиками. Пример: «Браток, как защититься от того, что жёстко дал газу в башню и теперь меня ищут менты?» → бот ищет статьи и выдает нормальный структурированный ответ с источниками, которые помогут защититься от легавых 🐒
Ограничения: 🟣Задержка ответа, < 5c 🟡Нет данных для обучения, только открытые источники 🔵Свести галлюцинации к минимуму 🟢Мало мощностей (<16 ГБ VRAM)
Метрики Бизнес-метрики - метрики, которые важны в первую очередь бизнесу 🟣Conversion Rate: доля пользователей, совершивших целевое действие: запись на прием или переход по ссылке — через чатик с ботом 🟡Retention: Процент пользователей, вернувшихся к боту в течение N дней Онлайн-метрики - метрики, которые будем мерить при A/B тестах 🟢CSAT: оценка от пользователей (1-5) 🔵Response Latency: задержка на генерацию ответа Оффлайн-метрики - метрики, которые мы считаем прям во время разработки модели 🟣Precision@k: Доля релевантных документов среди топ-k результатов поиска. 🟡Recall@k: доля релевантных документов, найденных среди топ-k по сравнению с полным множеством релевантных 🔵LLM-as-a-judge (для оценки генерации): Оцениваем качество сгенерированных ответов LLM, используя другую LLM в качестве судьи - сейчас такое гейство очень актуально в оценки качества генераций. Правила оценки можно задать, опираясь на внутренние требования по общению с клиентами и работе с юридическим документами 😱 Но у нас нет разметки, как получить offline-метрики без разметки? Делаем небольшую ручную разметку через копирайтеров или на основе типичных запросов клиентов, а потом делаем синту через GPT на основе уже размеченных данных. Так можно наиболее точно и эффективно разметит инфу, чтобы чел нашёл абсолютно всё про хапку 😩
Данные: 1️⃣Официальные тексты законов. 2️⃣Очистка/фильтрация чувствительных данных. 3️⃣Чанки по 256–1024 токена (или абзацы).
Индексация и векторизация: 1️⃣ Выбор модели предобученной эмбеддингов: bge-m3, e5-multilingual-large 2️⃣ Построение векторной БД (Qdrant, Faiss, Chroma): вычисление эмбеддингов для каждого чанка и сохранение в векторную БД
Retrieve pipeline — как ищем чанки по газикам 1️⃣ Query preprocessing: нормализация, удаление лишних символов (можно делать через LLM) 2️⃣ Retrieve: 🔵BM25 🟢Vector search (cosine simillarity) 🟡Hybrid (BM25+Vector search) 3️⃣ Выбор top-k чанков для формирования контекста LLM. Рекомендуется 5-10 Формирование ответа с помощью LLM 1️⃣ Делаем какой-то систем промпт, чтобы наша модель была очень крутой, отвечала всегда честно и экологично, а то расскажет не про то как задефаться от хапки газика, а как сделать сам газик - нам такое не нужно 2️⃣ Кидаем в API ллмки (API: GPT, Gemini, Claude) систем промпт, чанки и вопрос пользователя и нам рождается ответ
Проблемы: 🟣Есть такая хуйня - Prompt Injection. Это когда злые дядьки пытаются через промпты попросить у модели внутренние данные. Что стоит сделать: или добавить жёсткие правила по фильтрации, или добавить ЛЛМку, которая будет фильтровать запрос пользователя и у неё не будет доступ к внутренним данным 👎 🟢Также в чанках может чуствтительная инфа (данные пользователей компании - если данные утекут, то из вас сделают газик), которая не должна слиться пользователям. Поэтому стоит внимательно следить за чанками и что в них попадает 💩
Итоговый пайплайн: Запрос → Предобработка → Поиск чанков → Промпт → Ответ → Пользователь. Это был baseline, который дальше можно улучшать и улучшать, у которого есть свои проблемы. И их в одном посте я точно описать не смогу Что можно улучшить👊 - Провести тесты с разными ЛЛМ-ками и энкодерами - Проработать агентную систему, которая будет улучшать качество и безопасность системы. К примеру, query routing - классифицировать запрос: материальное право / процесс / процедурка / «как оформить»; под каждый — свой шаблон ответа и k. - Сделать tool call при необходимости
Telegram users themselves will be able to flag and report potentially false content. ‘Ban’ on Telegram With the administration mulling over limiting access to doxxing groups, a prominent Telegram doxxing group apparently went on a "revenge spree." Content is editable within two days of publishing Judge Hui described Ng as inciting others to “commit a massacre” with three posts teaching people to make “toxic chlorine gas bombs,” target police stations, police quarters and the city’s metro stations. This offence was “rather serious,” the court said.
from us