tgoop.com/dsproglib/6499
Create:
Last Update:
Last Update:
🧪 How-to: применить bootstrapping для оценки статистик
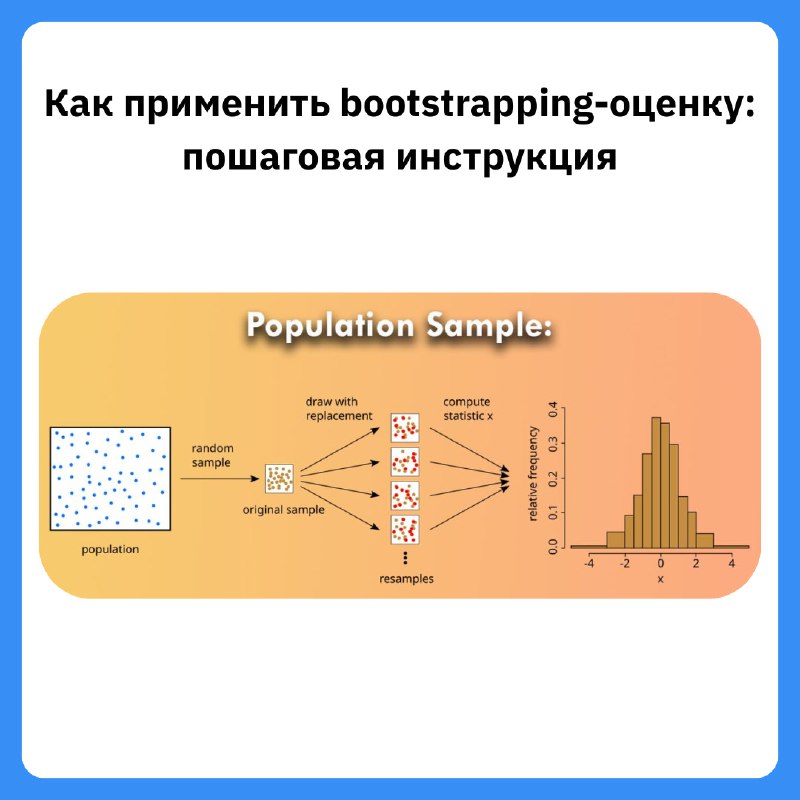
Когда данных немного или нет уверенности в распределении, bootstrapping приходит на помощь. Это техника, позволяющая оценить доверительные интервалы и стабильность метрик без строгих статистических предположений.
Мы будем многократно пересэмплировать нашу выборку с возвращением и оценивать интересующую статистику (среднее, медиану, разницу, корреляцию и т.д.).
import numpy as np
from sklearn.utils import resample
data = np.array([12, 15, 14, 10, 8, 11, 13]) # пример
boot_means = []
for _ in range(1000): # количество повторений
sample = resample(data, replace=True)
boot_means.append(np.mean(sample))
conf_int = np.percentile(boot_means, [2.5, 97.5])
print(f"95% доверительный интервал для среднего: {conf_int}")
✔️ Гибкость — можно применять к любым статистикам, особенно если неизвестно теоретическое распределение.
✔️ Без предположений — не требует априорных знаний о распределении в популяции.
✔️ Надёжность — работает даже при небольшом объёме выборки.
Библиотека дата-сайентиста #буст