tgoop.com/dsproglib/6301
Last Update:
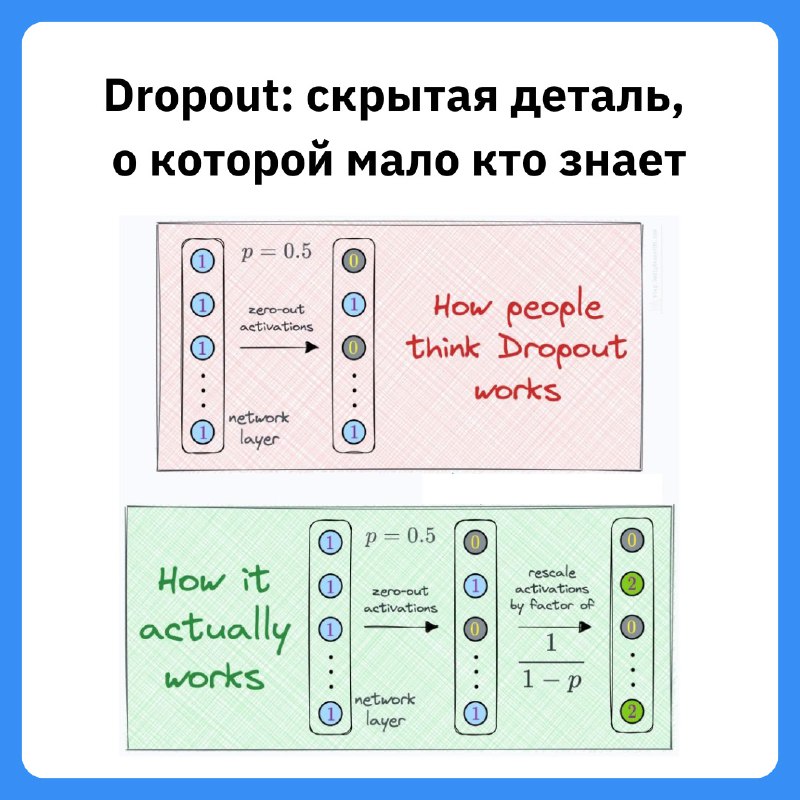
Если вы думаете, что Dropout просто обнуляет часть нейронов, это лишь половина правды. Есть ещё один важный шаг, который делает обучение стабильным.
— Представьте, что у нас есть 100 нейронов в предыдущем слое, все с активацией 1.
— Все веса соединений с нейроном A в следующем слое равны 1.
— Dropout = 50% — половина нейронов отключается во время обучения.
— Во время обучения: половина нейронов выключена, так что вход нейрона A ≈ 50.
— Во время inference: Dropout не применяется, вход A = 100.
Во время обучения нейрон получает меньший вход, чем во время inference. Это создаёт дисбаланс и может ухудшить обобщающую способность сети.
Чтобы это исправить, Dropout масштабирует оставшиеся активации во время обучения на коэффициент 1/(1-p), где p — доля отключённых нейронов.
— Dropout = 50% (p = 0.5).
— Вход 50 масштабируется: 50 / (1 - 0.5) = 100.
Теперь во время обучения вход нейрона A примерно соответствует тому, что он получит при inference. Это делает поведение сети стабильным.
import torch
import torch.nn as nn
dropout = nn.Dropout(p=0.5)
tensor = torch.ones(100)
# Обучение (train mode)
print(dropout(tensor).sum()) # ~100 (масштабировано)
# Вывод (eval mode)
dropout.eval()
print(dropout(tensor).sum()) # 100 (без Dropout)
В режиме обучения оставшиеся значения увеличиваются, в режиме inference — нет.
Dropout не просто отключает нейроны — он ещё масштабирует оставшиеся активации, чтобы модель обучалась корректно.
Библиотека дата-сайентиста #буст