tgoop.com »
United States »
Библиотека дата-сайентиста | Data Science, Machine learning, анализ данных, машинное обучение »
Telegram web »
Post 6265

🔄 Изменения в схеме данных: как избежать проблем для дата-команд
Мы рассмотрим четыре стратегии адаптации к изменениям и их возможные комбинации.
1. Встречи — самый простой подход
📌 Только коммуникация: команды источника данных и аналитики заранее обсуждают изменения, согласовывают сроки и схему данных перед внесением изменений в исходные наборы данных.
▪️ Плюсы:
— Самый простой подход
— Документирование в Confluence, Google Docs и т. д.
— Договоренность между командами
▪️ Минусы:
— Подвержен ошибкам
— Встречи замедляют процесс разработки
— Невозможно учесть все нюансы данных
🎯 Как реализовать:
— Фиксируйте договоренности в Confluence или Google Docs
— Включайте конкретные задачи и шаги для реализации изменений
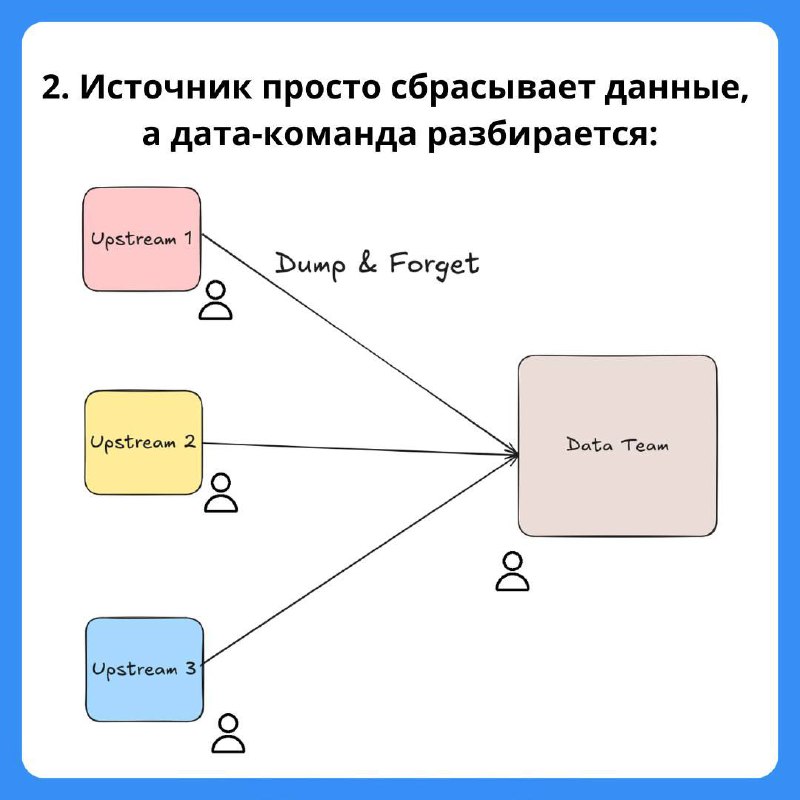
2. Источник просто сбрасывает данные, а дата-команда разбирается
📌 Dump & Forget: команда источника просто выгружает данные, а дата-команда работает с тем, что получает. Этот метод наиболее распространен в индустрии.
▪️Плюсы:
— Самый удобный способ для команды источника
— Позволяет источнику работать быстро
— Достаточно для большинства бизнес-кейсов
▪️Минусы:
— Дата-команда постоянно догоняет изменения
— Плохие данные, сбои конвейеров и технический долг
— Дата-команда теряет концептуальное понимание данных
🎯 Как реализовать:
— Используйте Apache Iceberg и Spark’s mergeSchema
— Для инструментов типа dbt включайте on_schema_change
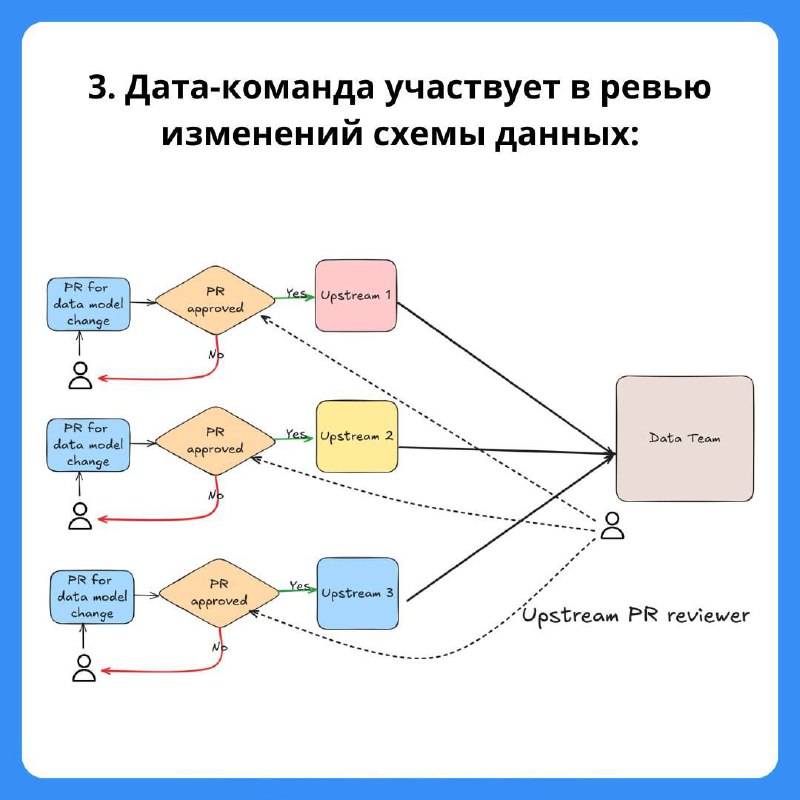
3. Дата-команда участвует в ревью изменений схемы данных
📌 Upstream Review: дата-команда участвует в моделировании данных источником. Как правило, дата-команды более внимательно относятся к проработке моделей данных.
▪️Плюсы:
— Предотвращает появление плохих данных
— Обеспечивает качественную схему данных
— Улучшает понимание данных между командами
▪️Минусы:
— Замедляет работу команды источника
— Не позволяет предотвратить агрегированные ошибки (например, несоответствие средней выручки за разные дни)
🎯 Как реализовать:
— Ускорьте процесс с помощью data contracts
— Используйте CODEOWNERS в GitHub, чтобы дата-команды участвовали в ревью
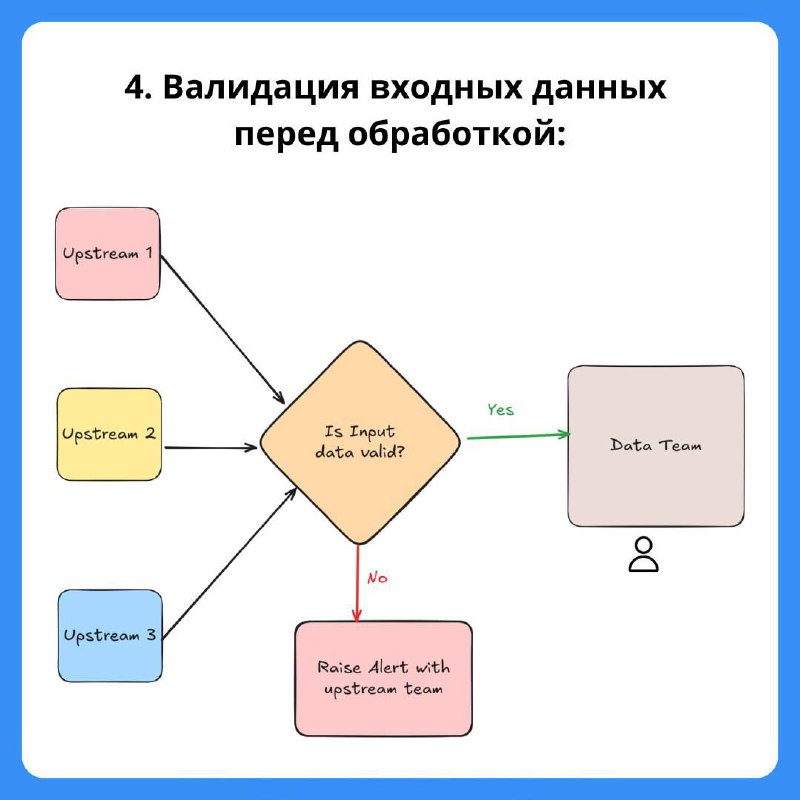
4. Валидация входных данных перед обработкой
📌 Input Validation: дата-команда проверяет входные данные перед их использованием. Если обнаруживается проблема, необходимо взаимодействовать с командой источника, чтобы исправить данные и повторно их обработать.
▪️ Плюсы:
— Быстрое обнаружение проблем
— Автоматизация отладки ошибок и уведомление команды источника
▪️ Минусы:
— Необходимо согласовывать проверки данных между командами
— Множественные проверки увеличивают время обработки данных
🎯 Как реализовать:
— Используйте любой инструмент контроля качества данных
— В потоковых системах применяйте DLQ (Dead Letter Queue) и реконсиляционные паттерны
Библиотека дата-сайентиста #буст
Мы рассмотрим четыре стратегии адаптации к изменениям и их возможные комбинации.
1. Встречи — самый простой подход
📌 Только коммуникация: команды источника данных и аналитики заранее обсуждают изменения, согласовывают сроки и схему данных перед внесением изменений в исходные наборы данных.
▪️ Плюсы:
— Самый простой подход
— Документирование в Confluence, Google Docs и т. д.
— Договоренность между командами
▪️ Минусы:
— Подвержен ошибкам
— Встречи замедляют процесс разработки
— Невозможно учесть все нюансы данных
🎯 Как реализовать:
— Фиксируйте договоренности в Confluence или Google Docs
— Включайте конкретные задачи и шаги для реализации изменений
2. Источник просто сбрасывает данные, а дата-команда разбирается
📌 Dump & Forget: команда источника просто выгружает данные, а дата-команда работает с тем, что получает. Этот метод наиболее распространен в индустрии.
▪️Плюсы:
— Самый удобный способ для команды источника
— Позволяет источнику работать быстро
— Достаточно для большинства бизнес-кейсов
▪️Минусы:
— Дата-команда постоянно догоняет изменения
— Плохие данные, сбои конвейеров и технический долг
— Дата-команда теряет концептуальное понимание данных
🎯 Как реализовать:
— Используйте Apache Iceberg и Spark’s mergeSchema
— Для инструментов типа dbt включайте on_schema_change
3. Дата-команда участвует в ревью изменений схемы данных
📌 Upstream Review: дата-команда участвует в моделировании данных источником. Как правило, дата-команды более внимательно относятся к проработке моделей данных.
▪️Плюсы:
— Предотвращает появление плохих данных
— Обеспечивает качественную схему данных
— Улучшает понимание данных между командами
▪️Минусы:
— Замедляет работу команды источника
— Не позволяет предотвратить агрегированные ошибки (например, несоответствие средней выручки за разные дни)
🎯 Как реализовать:
— Ускорьте процесс с помощью data contracts
— Используйте CODEOWNERS в GitHub, чтобы дата-команды участвовали в ревью
4. Валидация входных данных перед обработкой
📌 Input Validation: дата-команда проверяет входные данные перед их использованием. Если обнаруживается проблема, необходимо взаимодействовать с командой источника, чтобы исправить данные и повторно их обработать.
▪️ Плюсы:
— Быстрое обнаружение проблем
— Автоматизация отладки ошибок и уведомление команды источника
▪️ Минусы:
— Необходимо согласовывать проверки данных между командами
— Множественные проверки увеличивают время обработки данных
🎯 Как реализовать:
— Используйте любой инструмент контроля качества данных
— В потоковых системах применяйте DLQ (Dead Letter Queue) и реконсиляционные паттерны
Библиотека дата-сайентиста #буст
👍3❤1
tgoop.com/dsproglib/6265
Create:
Last Update:
Last Update:
🔄 Изменения в схеме данных: как избежать проблем для дата-команд
Мы рассмотрим четыре стратегии адаптации к изменениям и их возможные комбинации.
1. Встречи — самый простой подход
📌 Только коммуникация: команды источника данных и аналитики заранее обсуждают изменения, согласовывают сроки и схему данных перед внесением изменений в исходные наборы данных.
▪️ Плюсы:
— Самый простой подход
— Документирование в Confluence, Google Docs и т. д.
— Договоренность между командами
▪️ Минусы:
— Подвержен ошибкам
— Встречи замедляют процесс разработки
— Невозможно учесть все нюансы данных
🎯 Как реализовать:
— Фиксируйте договоренности в Confluence или Google Docs
— Включайте конкретные задачи и шаги для реализации изменений
2. Источник просто сбрасывает данные, а дата-команда разбирается
📌 Dump & Forget: команда источника просто выгружает данные, а дата-команда работает с тем, что получает. Этот метод наиболее распространен в индустрии.
▪️Плюсы:
— Самый удобный способ для команды источника
— Позволяет источнику работать быстро
— Достаточно для большинства бизнес-кейсов
▪️Минусы:
— Дата-команда постоянно догоняет изменения
— Плохие данные, сбои конвейеров и технический долг
— Дата-команда теряет концептуальное понимание данных
🎯 Как реализовать:
— Используйте Apache Iceberg и Spark’s mergeSchema
— Для инструментов типа dbt включайте on_schema_change
3. Дата-команда участвует в ревью изменений схемы данных
📌 Upstream Review: дата-команда участвует в моделировании данных источником. Как правило, дата-команды более внимательно относятся к проработке моделей данных.
▪️Плюсы:
— Предотвращает появление плохих данных
— Обеспечивает качественную схему данных
— Улучшает понимание данных между командами
▪️Минусы:
— Замедляет работу команды источника
— Не позволяет предотвратить агрегированные ошибки (например, несоответствие средней выручки за разные дни)
🎯 Как реализовать:
— Ускорьте процесс с помощью data contracts
— Используйте CODEOWNERS в GitHub, чтобы дата-команды участвовали в ревью
4. Валидация входных данных перед обработкой
📌 Input Validation: дата-команда проверяет входные данные перед их использованием. Если обнаруживается проблема, необходимо взаимодействовать с командой источника, чтобы исправить данные и повторно их обработать.
▪️ Плюсы:
— Быстрое обнаружение проблем
— Автоматизация отладки ошибок и уведомление команды источника
▪️ Минусы:
— Необходимо согласовывать проверки данных между командами
— Множественные проверки увеличивают время обработки данных
🎯 Как реализовать:
— Используйте любой инструмент контроля качества данных
— В потоковых системах применяйте DLQ (Dead Letter Queue) и реконсиляционные паттерны
Библиотека дата-сайентиста #буст
Мы рассмотрим четыре стратегии адаптации к изменениям и их возможные комбинации.
1. Встречи — самый простой подход
📌 Только коммуникация: команды источника данных и аналитики заранее обсуждают изменения, согласовывают сроки и схему данных перед внесением изменений в исходные наборы данных.
▪️ Плюсы:
— Самый простой подход
— Документирование в Confluence, Google Docs и т. д.
— Договоренность между командами
▪️ Минусы:
— Подвержен ошибкам
— Встречи замедляют процесс разработки
— Невозможно учесть все нюансы данных
🎯 Как реализовать:
— Фиксируйте договоренности в Confluence или Google Docs
— Включайте конкретные задачи и шаги для реализации изменений
2. Источник просто сбрасывает данные, а дата-команда разбирается
📌 Dump & Forget: команда источника просто выгружает данные, а дата-команда работает с тем, что получает. Этот метод наиболее распространен в индустрии.
▪️Плюсы:
— Самый удобный способ для команды источника
— Позволяет источнику работать быстро
— Достаточно для большинства бизнес-кейсов
▪️Минусы:
— Дата-команда постоянно догоняет изменения
— Плохие данные, сбои конвейеров и технический долг
— Дата-команда теряет концептуальное понимание данных
🎯 Как реализовать:
— Используйте Apache Iceberg и Spark’s mergeSchema
— Для инструментов типа dbt включайте on_schema_change
3. Дата-команда участвует в ревью изменений схемы данных
📌 Upstream Review: дата-команда участвует в моделировании данных источником. Как правило, дата-команды более внимательно относятся к проработке моделей данных.
▪️Плюсы:
— Предотвращает появление плохих данных
— Обеспечивает качественную схему данных
— Улучшает понимание данных между командами
▪️Минусы:
— Замедляет работу команды источника
— Не позволяет предотвратить агрегированные ошибки (например, несоответствие средней выручки за разные дни)
🎯 Как реализовать:
— Ускорьте процесс с помощью data contracts
— Используйте CODEOWNERS в GitHub, чтобы дата-команды участвовали в ревью
4. Валидация входных данных перед обработкой
📌 Input Validation: дата-команда проверяет входные данные перед их использованием. Если обнаруживается проблема, необходимо взаимодействовать с командой источника, чтобы исправить данные и повторно их обработать.
▪️ Плюсы:
— Быстрое обнаружение проблем
— Автоматизация отладки ошибок и уведомление команды источника
▪️ Минусы:
— Необходимо согласовывать проверки данных между командами
— Множественные проверки увеличивают время обработки данных
🎯 Как реализовать:
— Используйте любой инструмент контроля качества данных
— В потоковых системах применяйте DLQ (Dead Letter Queue) и реконсиляционные паттерны
Библиотека дата-сайентиста #буст
BY Библиотека дата-сайентиста | Data Science, Machine learning, анализ данных, машинное обучение


Share with your friend now:
tgoop.com/dsproglib/6265