
tgoop.com/dsproglib/6127
Last Update:
Shuffle Feature Importance: простая методика оценки важности признаков
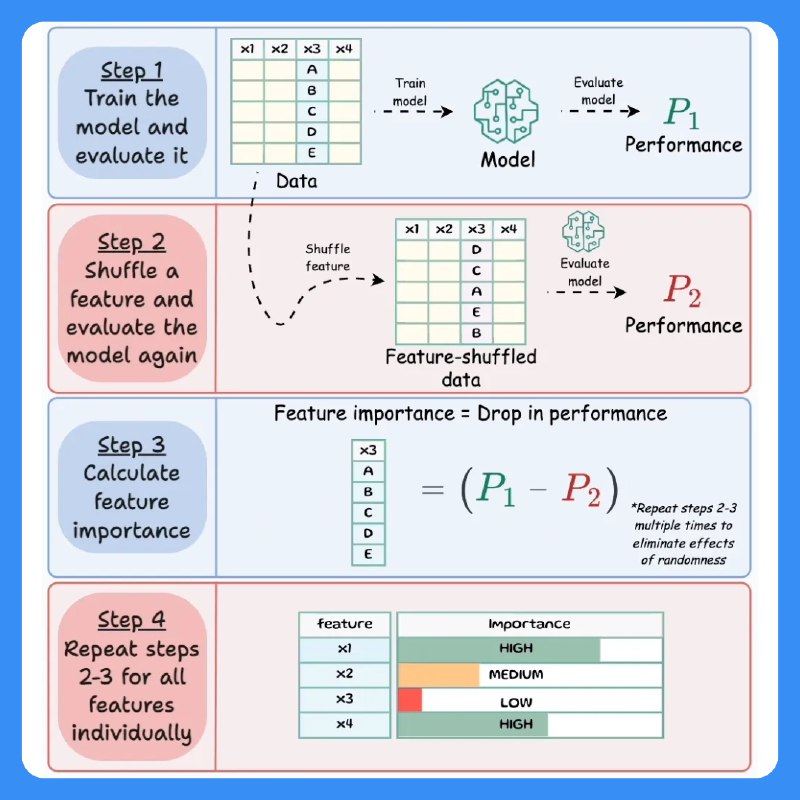
Shuffle Feature Importance — интуитивно понятный метод оценки значимости признаков в модели машинного обучения. Он основан на анализе того, насколько ухудшается качество модели после случайного перемешивания значений конкретного признака.
Как это работает:
▪️ Обучение модели и оценка её качества (P₁) на исходных данных.
▪️ Перемешивание одного признака (shuffle) и повторная оценка качества модели (P₂).
▪️ Расчёт важности признака: разница между исходным и новым качеством модели (P₁ — P₂).
▪️ Повторение процедуры для всех признаков, чтобы получить сравнительную значимость.
📊 Чем сильнее падает качество после перемешивания, тем важнее признак для модели!
BY Библиотека дата-сайентиста | Data Science, Machine learning, анализ данных, машинное обучение
Share with your friend now:
tgoop.com/dsproglib/6127