
tgoop.com/dlinnlp/1484
Last Update:
A Watermark for Large Language Models
arxiv.org/abs/2301.10226
Когда GPT3-подобные модели станут повседневностью, что активно начал ChatGPT, вопрос детекции сгенерированного кода может быть критическим. И причины тому простые: плагиаризм (в широком смысле) и нежелание школьной системы адаптироваться (в частности).
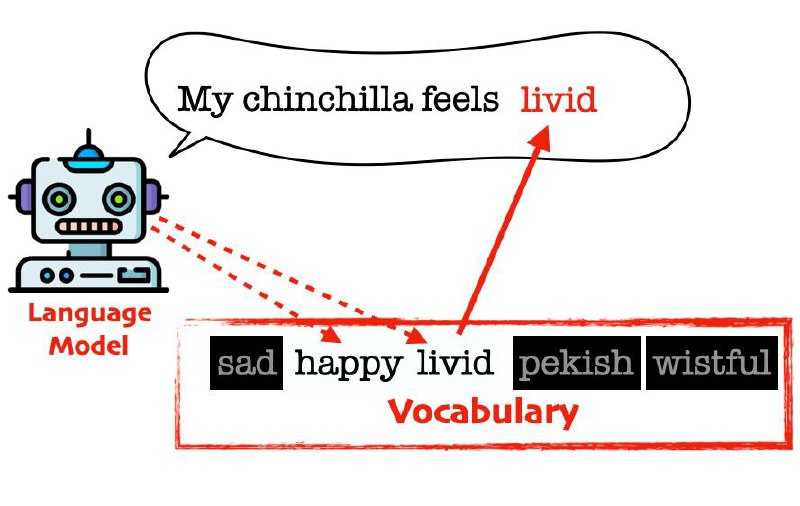
В этой статье предлагают следующий подход: при генерации следующего слова на предыдущем слове считается хеш, который инициализиурет генератор случайных чисел. Зачем этот генератор случайно маскирует 75% слов из словаря модели и позволяет генерировать только оставшиеся 25%. Далее, зная функцию хеширования мы можем по тексту статистически определить сгенерирован ли он моделью с высокой точностью если текст больше ~30 слов.
Но возникает вопрос: а что если модель генерирует Spongebob Square <...> и слово Pants не попало в whitelist? Для того чтобы высокочастотыне слова всё равно генерировались вместо жёсткого разделения на whitelist/blacklist вероятность слов в словаре модифицируют более мягко — добавляя некоторую константу (например 1.0) к лог-вероятностям whitelist слов. Статистические тесты всё ещё работают, но теперь высоковероятные слова генерируются даже если они не попали в whitelist.
Эта статья от исследователей из University of Maryland. Интересно что им противопоставит OpenAI которые тоже активно работают над этой технологией.
BY DL in NLP
Share with your friend now:
tgoop.com/dlinnlp/1484