
#работы_студентов
Выкладываю ещё один диплом моей студентки — Анастасии Рагулиной. Настя — Data Scientist, и до курса не работала в графических редакторах, а её графики были очень простыми и не всегда оптимальными. Поэтому я уверен, что при должном желании и упорстве можно за пару месяцев очень круто прокачаться в визуализации. Вот что она говорит о своей работе:
Эта работа — хороший пример, как из большого количества хаотичных данных можно сделать увлекательную и красивую историю. Если хотите научиться так же, приходите ко мне на курс — будем практиковаться: https://clck.ru/3Bc8in
Выкладываю ещё один диплом моей студентки — Анастасии Рагулиной. Настя — Data Scientist, и до курса не работала в графических редакторах, а её графики были очень простыми и не всегда оптимальными. Поэтому я уверен, что при должном желании и упорстве можно за пару месяцев очень круто прокачаться в визуализации. Вот что она говорит о своей работе:
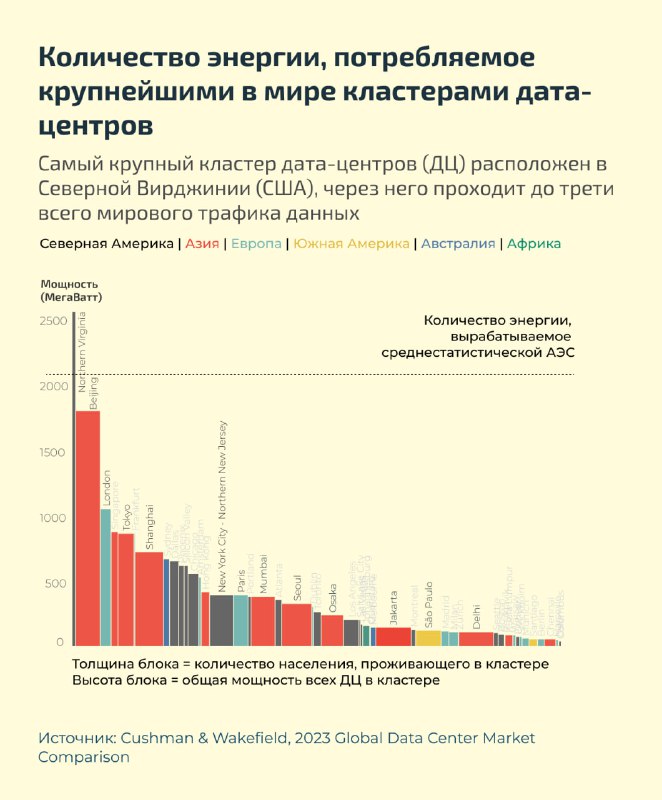
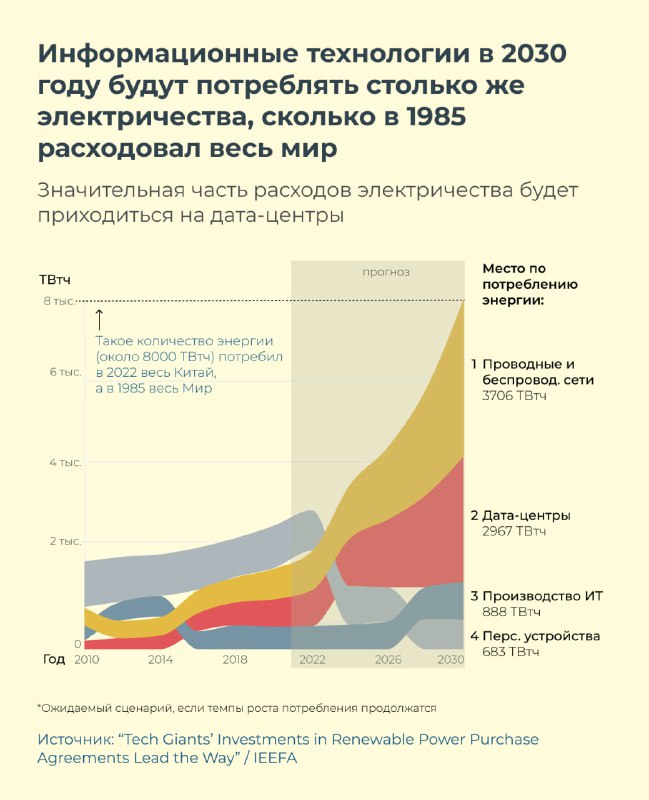
В последнее время тема ИИ будоражит многих. Мне захотелось взглянуть на проблему не с точки зрения «нейросети поработят нас всех», а с более приземлённой стороны. Модели выходят всё чаще, и все они обучаются на невообразимых количествах параметров.
Облака данных расположены не на небе, а в Дата-центрах, на серверах, которые, как оказалось, требуют огромного количества энергии для своего функционирования (и воды для охлаждения, но это тема для отдельной истории). Один запрос в Google расходует ничтожное количество энергии. Однако каждую секунду (!) поступают миллионы таких запросов.
Для меня это был повод разобраться самой и показать другим, что такая проблема существует и со временем она может стать существенной.
Эта работа — хороший пример, как из большого количества хаотичных данных можно сделать увлекательную и красивую историю. Если хотите научиться так же, приходите ко мне на курс — будем практиковаться: https://clck.ru/3Bc8in
👍41🔥29❤14
tgoop.com/data_csv/1408
Create:
Last Update:
Last Update:
#работы_студентов
Выкладываю ещё один диплом моей студентки — Анастасии Рагулиной. Настя — Data Scientist, и до курса не работала в графических редакторах, а её графики были очень простыми и не всегда оптимальными. Поэтому я уверен, что при должном желании и упорстве можно за пару месяцев очень круто прокачаться в визуализации. Вот что она говорит о своей работе:
Эта работа — хороший пример, как из большого количества хаотичных данных можно сделать увлекательную и красивую историю. Если хотите научиться так же, приходите ко мне на курс — будем практиковаться: https://clck.ru/3Bc8in
Выкладываю ещё один диплом моей студентки — Анастасии Рагулиной. Настя — Data Scientist, и до курса не работала в графических редакторах, а её графики были очень простыми и не всегда оптимальными. Поэтому я уверен, что при должном желании и упорстве можно за пару месяцев очень круто прокачаться в визуализации. Вот что она говорит о своей работе:
В последнее время тема ИИ будоражит многих. Мне захотелось взглянуть на проблему не с точки зрения «нейросети поработят нас всех», а с более приземлённой стороны. Модели выходят всё чаще, и все они обучаются на невообразимых количествах параметров.
Облака данных расположены не на небе, а в Дата-центрах, на серверах, которые, как оказалось, требуют огромного количества энергии для своего функционирования (и воды для охлаждения, но это тема для отдельной истории). Один запрос в Google расходует ничтожное количество энергии. Однако каждую секунду (!) поступают миллионы таких запросов.
Для меня это был повод разобраться самой и показать другим, что такая проблема существует и со временем она может стать существенной.
Эта работа — хороший пример, как из большого количества хаотичных данных можно сделать увлекательную и красивую историю. Если хотите научиться так же, приходите ко мне на курс — будем практиковаться: https://clck.ru/3Bc8in
BY data.csv



Share with your friend now:
tgoop.com/data_csv/1408