
tgoop.com/cats_shredinger/124
Last Update:
Stack More Layers Differently: High-Rank Training Through Low-Rank Updates
Статья: arxiv.org/abs/2307.05695
Код: GitHub
Мы задались вопросом: если LoRA настолько хороша для файнтюнинга, можем ли мы применить её для претренинга?
Мы представляем ReLoRA — первый метод PEFT, который может использоваться для обучения с нуля! 🔥
Почему мы не можем использовать LoRA для претренинга? Потому что он оптимизирует только в маленьком подпространстве низкого ранга параметров модели. Этого достаточно для файнтюнинга, но не для претренинга. Что мы можем сделать?
Применить LoRA несколько раз подряд. Это работает, потому что параметры LoRA могут быть интегрированы в основную сеть (W += W_A @ W_B) и потому что сумма матриц низкого ранга может иметь ранг больше, ранги слагаемых.
Но теперь у нас новая проблема: оптимизаторы сильно полагаются на momentum который и определяет большую часть направления апдейта по предыдущим градиентам (а не текущему градиенту). Это делает шаги оптимизации сильно скоррелированными
Представьте первый шаг оптимизации после ресета ReLoRA. Он сделает параметры ReLoRA похожими на параметры предыдущей итерации. Это потенциально может "заполнить ранг" параметров LoRA и минимально увеличить суммарный ранг. Поэтому при ресете ReLoRA мы частично ресетим стейт оптимизатора сохраняя только 0-10% весов. Далее, чтобы избежать нестабильностей мы прогреваем LR 10-50 шагов
LayerNorm и эмбеддинги тренируются как обычно, без репараметризации. Наконец, ранняя фаза обучения очень важна, и нам действительно нужно "подогреть" сеть с помощью обычного полноценного обучения. На практике достаточно 3-5 тысяч шагов
TL;DR
1. LoRA + ресеты
1. Частичный сброс стейта оптимизатора
1. "Зубчатый" LR scheduler
1. Прогрев через обычную тренировку
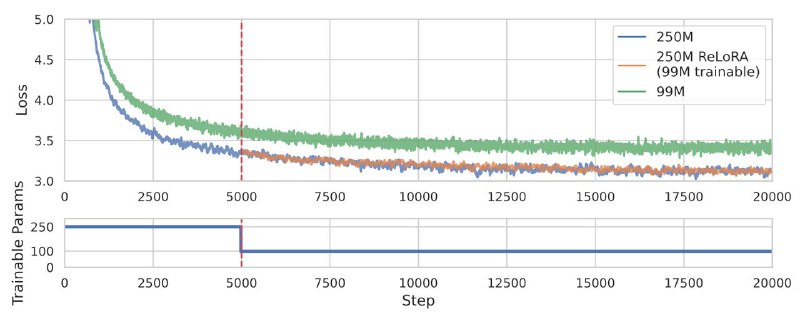
На совсем маленьких сетках всё грустно, но начиная с 250M метод начинает работать близко к обычной тренировке. На 1B видим уменьшение потребления RAM и ускорение на 50%. Сейчас ищем компьют на тренировку 1B-модели
Буду рад ретвиту вот этого треда — продвигать статьи это довольно сложно 😅
BY Шрёдингер Кота
Share with your friend now:
tgoop.com/cats_shredinger/124