tgoop.com/bigdatai/999
Last Update:
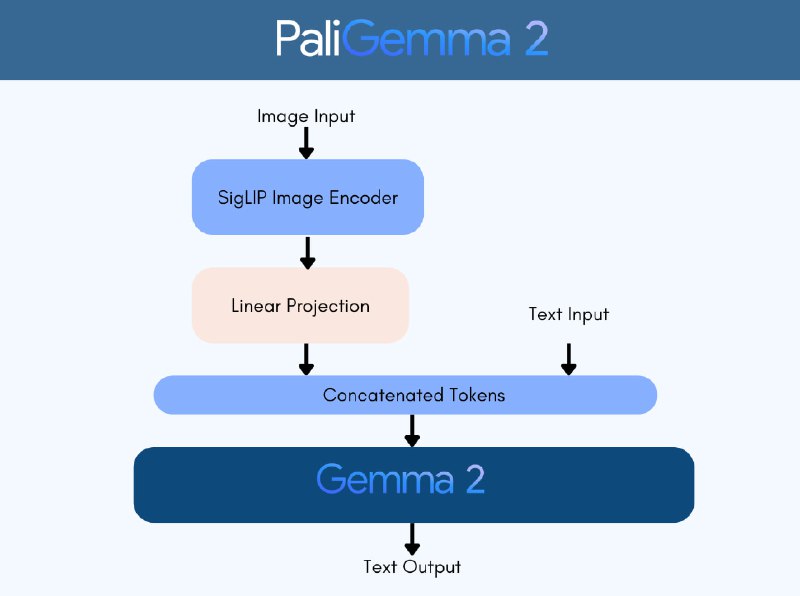
PaliGemma 2 - обновление open-sorce VLM PaliGemma, основанное на семействе LLM Gemma 2. Семейство сочетает в себе кодировщик изображений SigLIP-So400m с спектром моделей Gemma 2, от 2B до 27B параметров. Модели PaliGemma 2 обучались в 3 этапа на трех разрешениях (224px², 448px² и 896px²).
PaliGemma 2 демонстрирует впечатляющие результаты в распознавании музыкальных нот, молекулярных структур и медицинских изображений. Модели справляются с распознаванием табличной структуры и созданием отчетов по рентгенограммам.
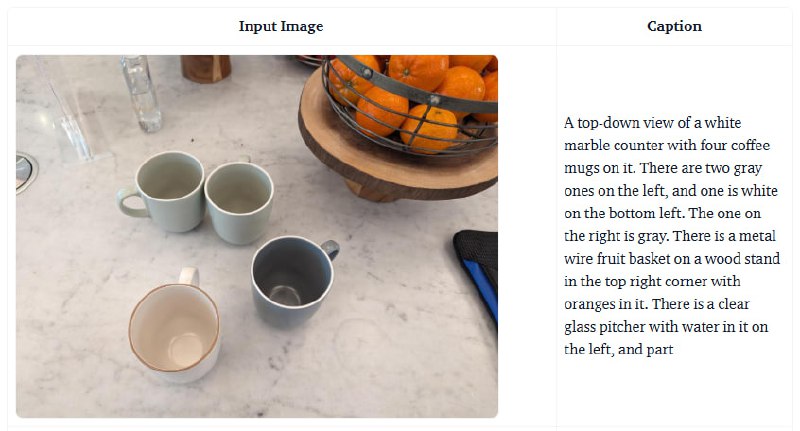
В задачах генерации длинных, детализированных аннотаций к изображениям PaliGemma 2 превосходит многие популярные VLM, несмотря на то, что она обучалась на значительно меньших наборах данных.
Для развертывания на устройствах без GPU могут использоваться квартованные версии PaliGemma 2. Тесты показали, что переход от 32-битной разрядности (f32) к 16-битной (bf16) или квантованным весам не приводит к заметному снижению качества.
В релиз вошли предварительно обученные модели 3B, 10B и 28B с разрешениями 224px, 448px, 896px, модели, настроенные на наборе данных DOCCI для создания аннотаций к изображениям и их версии для JAX/FLAX.
Процесс файнтюна PaliGemma 2 такой же, как и у предыдущей версии. Разработчики предоставляют скрипт и ipynb-блокнот для тонкой настройки модели или создания LoRA/QLoRA.
Создание LoRA модели PaliGemma 2 на половине валидационного сплита VQAv2 заняло полчаса на 3-х A100 с 80 ГБ VRAM. Результат можно найти здесь, а это ее демо.paligemma2-10b-ft-docci-448 на Transformers:
from transformers import AutoProcessor, PaliGemmaForConditionalGeneration
from PIL import Image
import requests
model_id = "google/paligemma2-10b-ft-docci-448"
model = PaliGemmaForConditionalGeneration.from_pretrained(model_id)
model = model.to("cuda")
processor = AutoProcessor.from_pretrained(model_id)
prompt = "<image>caption en"
image_file = "% link_to_target_file%"
raw_image = Image.open(requests.get(image_file, stream=True).raw).convert("RGB")
inputs = processor(prompt, raw_image, return_tensors="pt").to("cuda")
output = model.generate(**inputs, max_new_tokens=20)
print(processor.decode(output[0], skip_special_tokens=True)[len(prompt):])
@ai_machinelearning_big_data
#AI #ML #VLM #Google #PaliGemma